-
법률문서의 주제 모델링과 요약을 위한 NLPARCHIVE/MACHINE LEARNING 2018. 2. 2. 07:30반응형
이 문서는 영문으로된 내용을 카카오 번역기를 활용하여 번역한 내용입니다.
개인적인 공부 및 추후 다시 볼 수 있도록 하기 위해 개인 블로그에 번역 내용을 옮겨 놓았습니다.
원문과 내용이 다를시 책임지지 않으며, 저작권 문제가 발생시 언제든 삭제 될 수 있습니다.원문보기 : https://towardsdatascience.com/nlp-for-topic-modeling-summarization-of-legal-documents-8c89393b1534
법률문서의 주제 모델링과 요약을 위한 NLP
변호사들이 어떻게 일련의 법정 진술을 효과적으로 관리할 수 있는지 궁금한 적이 있나요? 결국 법률문서의 일반적인 맥락을 어떻게 이해하여 궁극적으로 그것을 취해야 하는지를 미리 파악해야합니다. 3000페이지의 문서를 가지고 있기 전까지는 아주 쉬운 것 같았습니다. 이것은 이 프로젝트의 동기였습니다. 법률 문서의 PDF에서 주제를 자동으로 모델링하고 주요 컨텍스트를 요약하는 것이었습니다.
이 프로젝트는 어느 당사자도 찬성하거나 그렇지 않은 주제 컨텍스트를 추출하기 위해 두 당사자 간의 5 페이지로된 TRADEMARK 및 DOMAIN NAME AGREEMEMENT에서 주제 모델링을 자동화하는 것을 목표로합니다. 이 접근법은 문서의 PDF 사본에서 텍스트 추출, 추출된 텍스트 정리, 문서에서 주제 모델링 및 시각적 요약 표시와 관련이 있습니다. 여기에 채택된 접근 방식은 pdf로 저장된 문서에 대해 확장할 수 있습니다.
PDF 문서로부터의 텍스트 추출
양 당사자 간의 법적 합의는 PDF 문서로 제공되었습니다. PDF 문서의 텍스트는 먼저 아래 표시된 함수를 사용하여 추출되었습니다. 이 함수는 파이썬 라이브러리 pdf-miner를 사용하여 이미지 (이를 수용하기 위해 수정할 수는 있지만)를 제외한 PDF 문서의 모든 문자를 가져옵니다. 이 함수는 홈 디렉토리의 pdf 문서 이름을 간단히 취하고 모든 문자를 추출하여 추출된 텍스트를 문자열의 파이썬 목록으로 출력합니다.
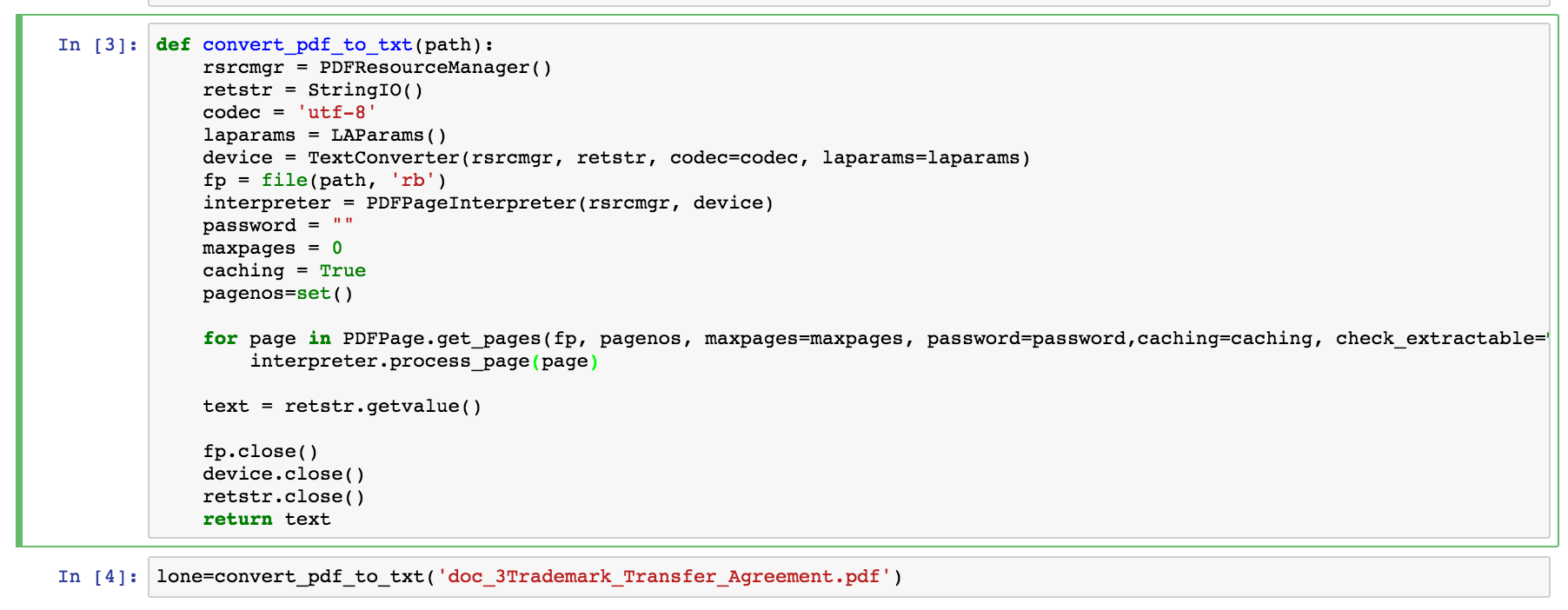
그림, PDF 문서에서 텍스트를 추출하는 기능을 보여줍니다.
추출된 텍스트 정리
PDF 문서에서 추출한 텍스트에는 제거해야 하는, 정보가 없는 문자가 들어 있습니다. 이러한 문자는 불필요한 카운트 비율을 제공하므로 모델의 효율성을 감소시킵니다. 아래 함수는 일련의 regex 검색 및 바꾸기 기능과 list-comprehension을 사용하여 이러한 문자를 공백으로 대체합니다. 아래의 함수는 이 프로세스에 사용되었으며 표시된 결과 문서에는 영문/숫자 만 포함됩니다.

그림, 문서 코딩을 빈 공간으로 대체하는 코드를 보여줍니다.

그림, 알파벳이 아닌 문자를 빈문자로 대체하는 코드를 보여줍니다.
주제 모델링
Scikit-Learn 모듈의 CountVectorizer는 깨끗한 문서를 DocumentTermMatrix로 표현하기 위해 최소한의 매개 변수 조정과 함께 사용되었습니다. 이는 모델링을 위해서는 문자열을 정수로 표현해야하기 때문입니다. CountVectorizer는 stop-words를 제거한 후 목록에서 단어가 발생하는 횟수를 보여줍니다.
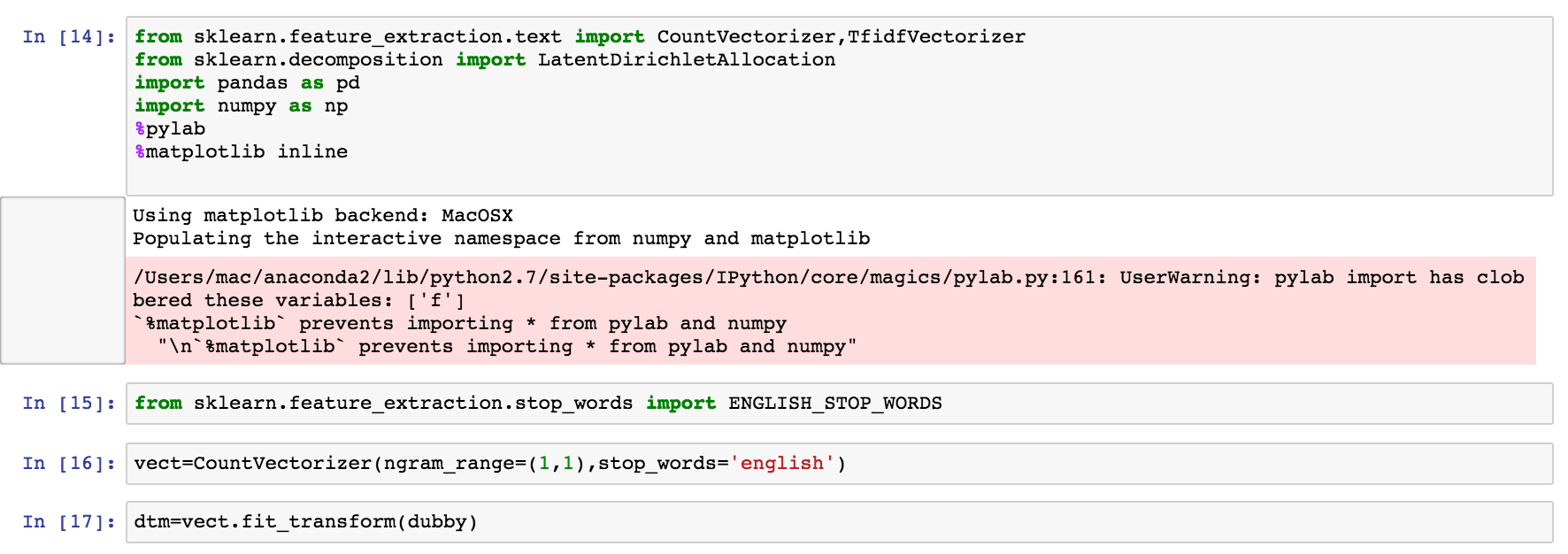
그림, CountVectorizer가 stop-words가 있는 문서에 어떻게 맞춰졌는지 보여줍니다.
문서 용어 행렬은 아래 표시된 데이터 집합을 흘끗 보기 위해 팬더 데이터 프레임으로 형식화되었습니다. 이 데이터 프레임은 문서에서 각 용어의 단어 발생 횟수를 보여줍니다. 데이터 프레임으로 형식화되지 않으면 문서 용어 행렬은 희소 행렬(sparse-matrix)로 존재하며 Scipy의 todense() 또는 toarray()를 사용하여 고밀도 행렬(dense-martix)로 변환해야합니다.
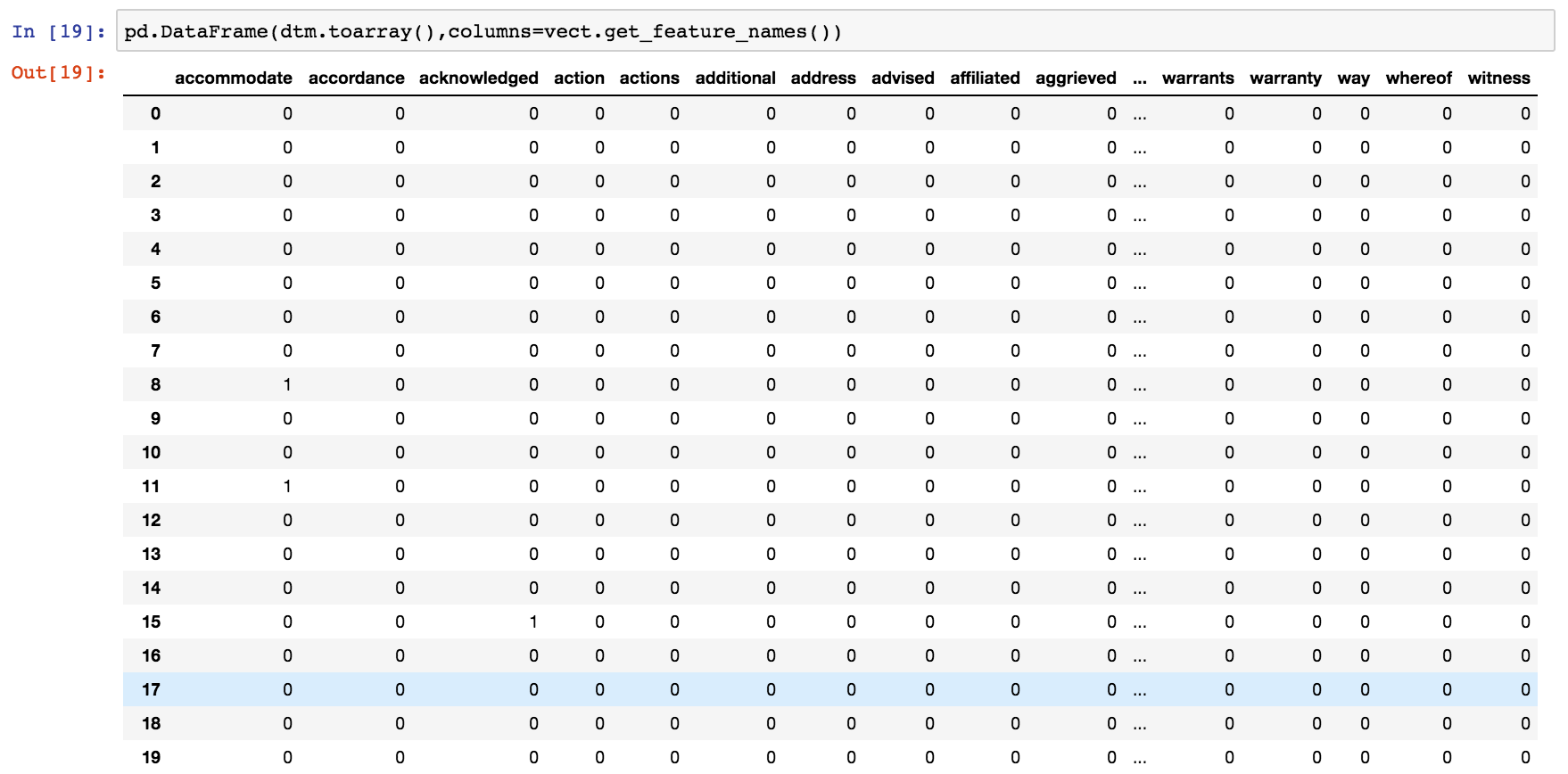
그림, CountVectorizer에서 나온 출력의 단면을 보여줍니다.
이 문서 용어 행렬은 주제 모델링을 위해 Latent Dirichlet Allocation 알고리즘에서 사용할 입력 데이터로 사용되었습니다. 이 LDA 알고리즘에는 몇 가지 다른 도구가 있지만, 이 프로젝트에서는 scikit-learn 을 사용할 것입니다. 또 다른 유명한 LDA 구현은 Radim Rehurek의 gensim입니다. 이것은 CountVectorizer에서 출력 한 문서 용어 행렬에 적합합니다. 이 알고리즘은 아래 코드와 같이 5 가지 고유 주제 컨텍스트를 분리하기 위해 적합했습니다. 이 값은 모델링에서 얻을 세분화 수준에 따라 변경 될 수 있습니다.
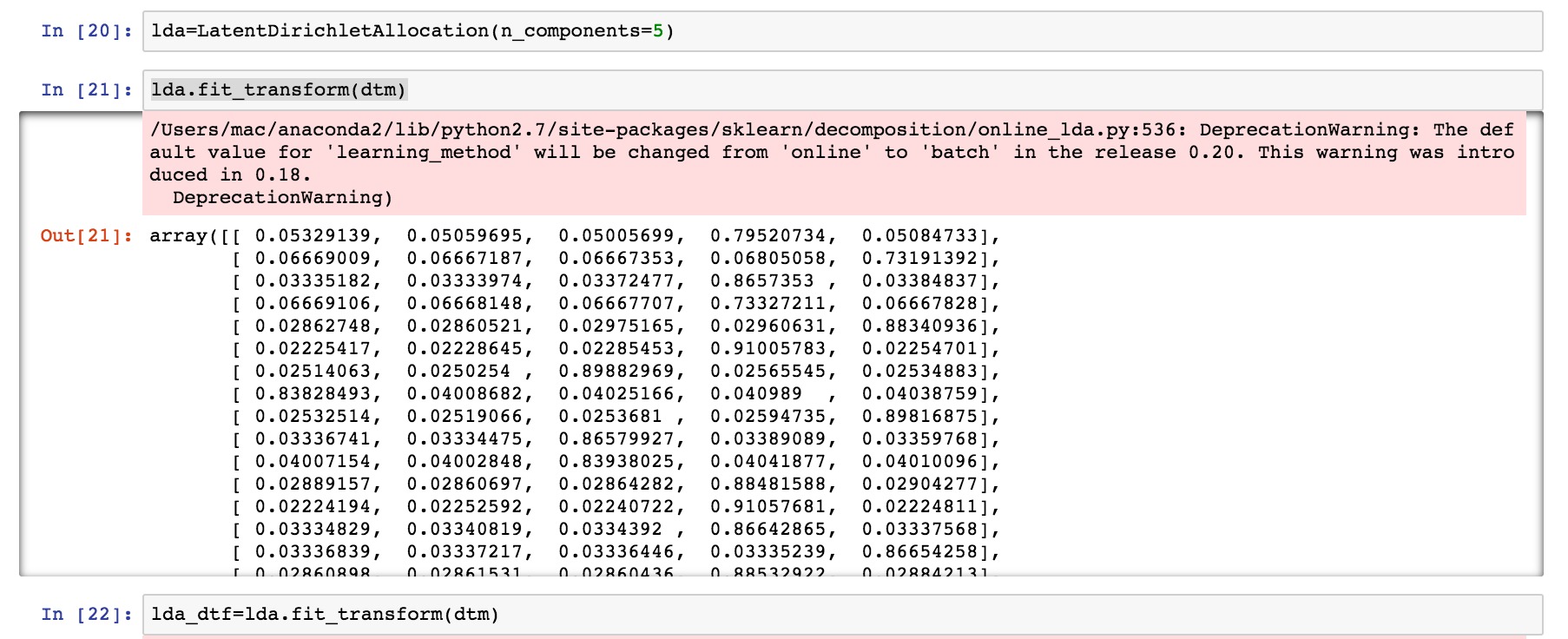
그림. LDA 모델이 DocumentTermMatrix에 5가지 주제로 어떻게 적용되었는지 보여줍니다.
아래 코드는 mglearn 라이브러리를 사용하여 각 특정 주제 모델 내에 상위 10 개 단어를 표시합니다. 각 주제가 제시된 단어에서 요약한 결론을 쉽게 이끌어 낼 수 있습니다.
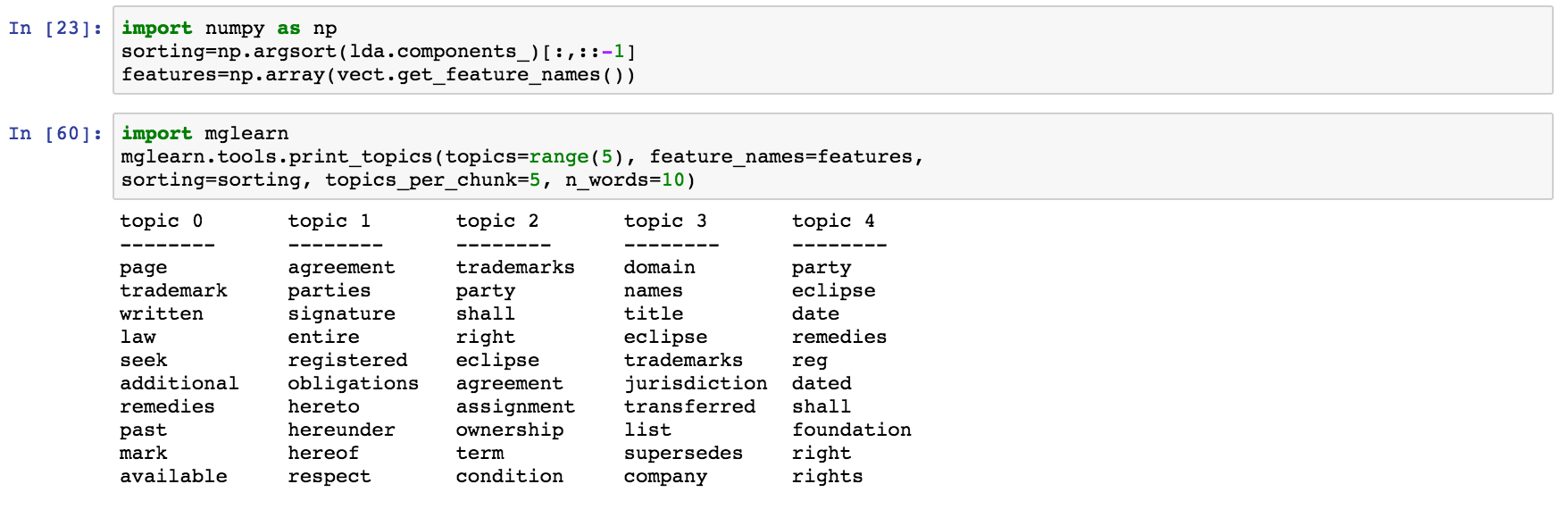
그림. LDA의 5개 주제와 각 주제에서 가장 흔한 단어를 보여줍니다
위의 결과에서 Topic-2는 상표 소유권 계약 조건 및 조건과 관련이 있습니다. Topic-1은 서명과 일부 의무가 관련된 당사자 간의 합의에 대해 이야기합니다. ECLIPSE라는 단어는 전체 문서에서 관련이 있음을 나타내는 다섯 가지 주제 모두에서 널리 퍼져있는 것으로 보입니다.
이 결과는 문서와 매우 일치합니다 (TRADEMARK 및 DOMAIN NAME AGREEMENT).
각 주제를 더 복잡하게 관찰하기 위해 각 주제 모델과 함께 문장을 추출하여 간략한 요약을합니다. 아래의 코드는 Topic의 1과 4에서 상위 4 개의 문장을 추출합니다.
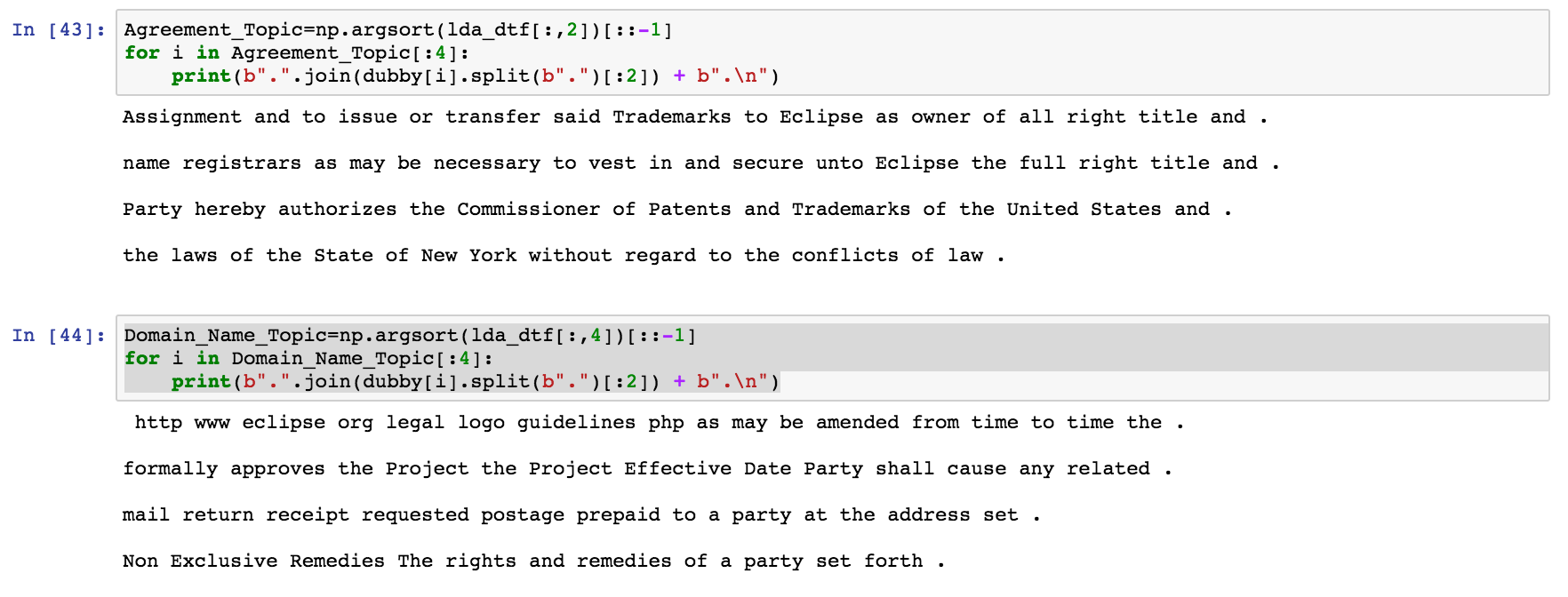
그림, 주제 모델 1과 4에 문장을 표시
Topic-1의 문장은 뉴욕시의 법률에 따라 상표를 할당하는 것에 대해 이야기합니다.
또한, 주제 4의 문장은 도메인 이름과 상표 계약의 유효 날짜를 명확하게 보여줍니다.
결과 시각화
PyldaVis 라이브러리는 주제 모델을 시각화하는 데 사용되었습니다. 주제의 1과 4가 얼마나 밀접한 관련이 있는지, 주제 2, 3, 5가 서로 얼마나 먼 지 주목하십시오. 이 주제 (2, 3 및 5)는 법률 문서에서 상대적으로 다른 주제를 포착하며 결합 될 때 문서에 대한 광범위한 견해를 제공하므로보다 복잡하게 관찰해야하는 주제입니다.
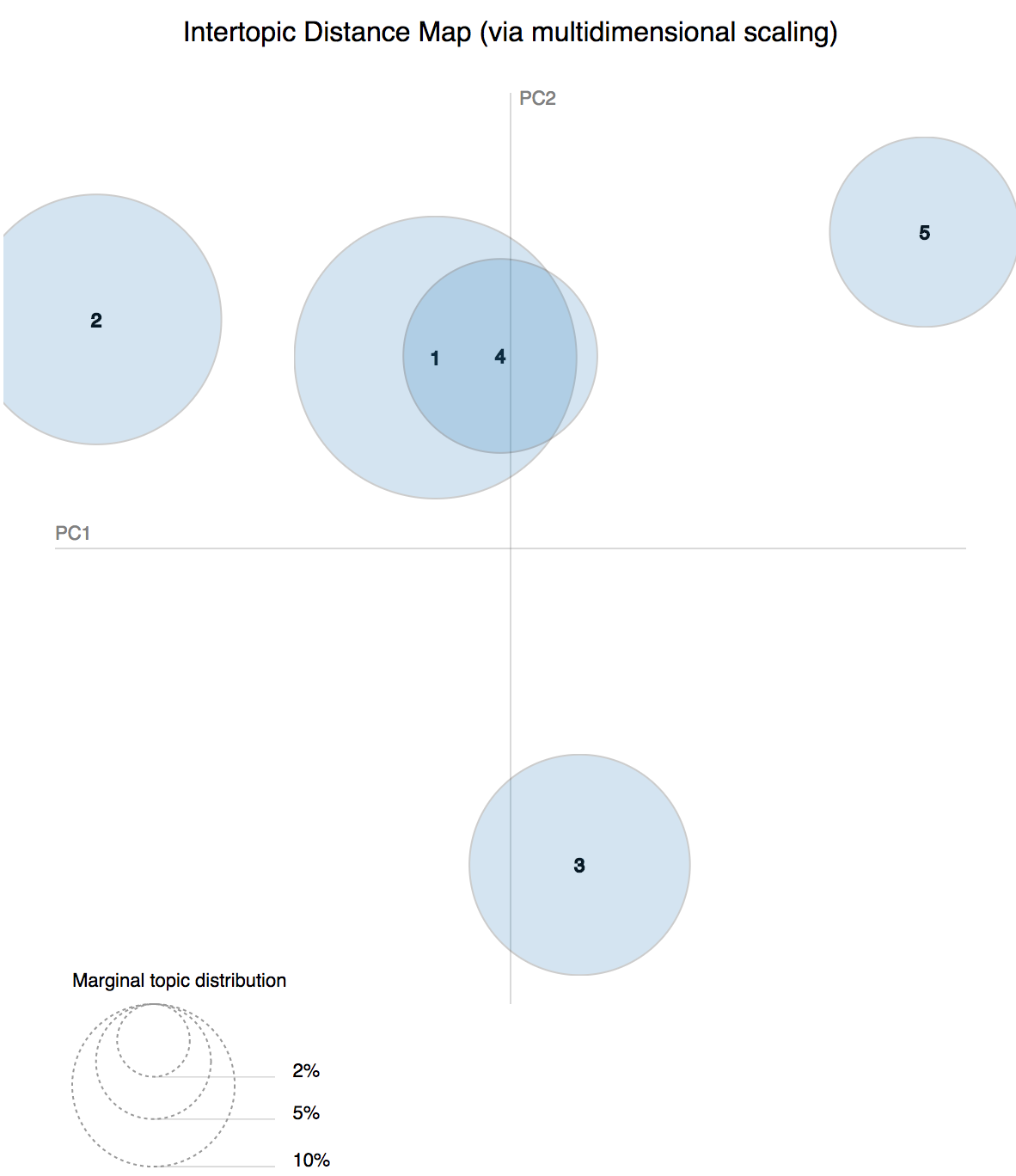
그림, 각 모델링된 주제가 서로 얼마나 다른지를 보여줍니다
아래 다이어그램에서 Topic-5는 Topic-3이 도메인 이름, 제목 및 상표에 대해 이야기하는 동안 양 당사자 간의 계약, 의무 및 서명에 관한 주제를 나타냅니다.
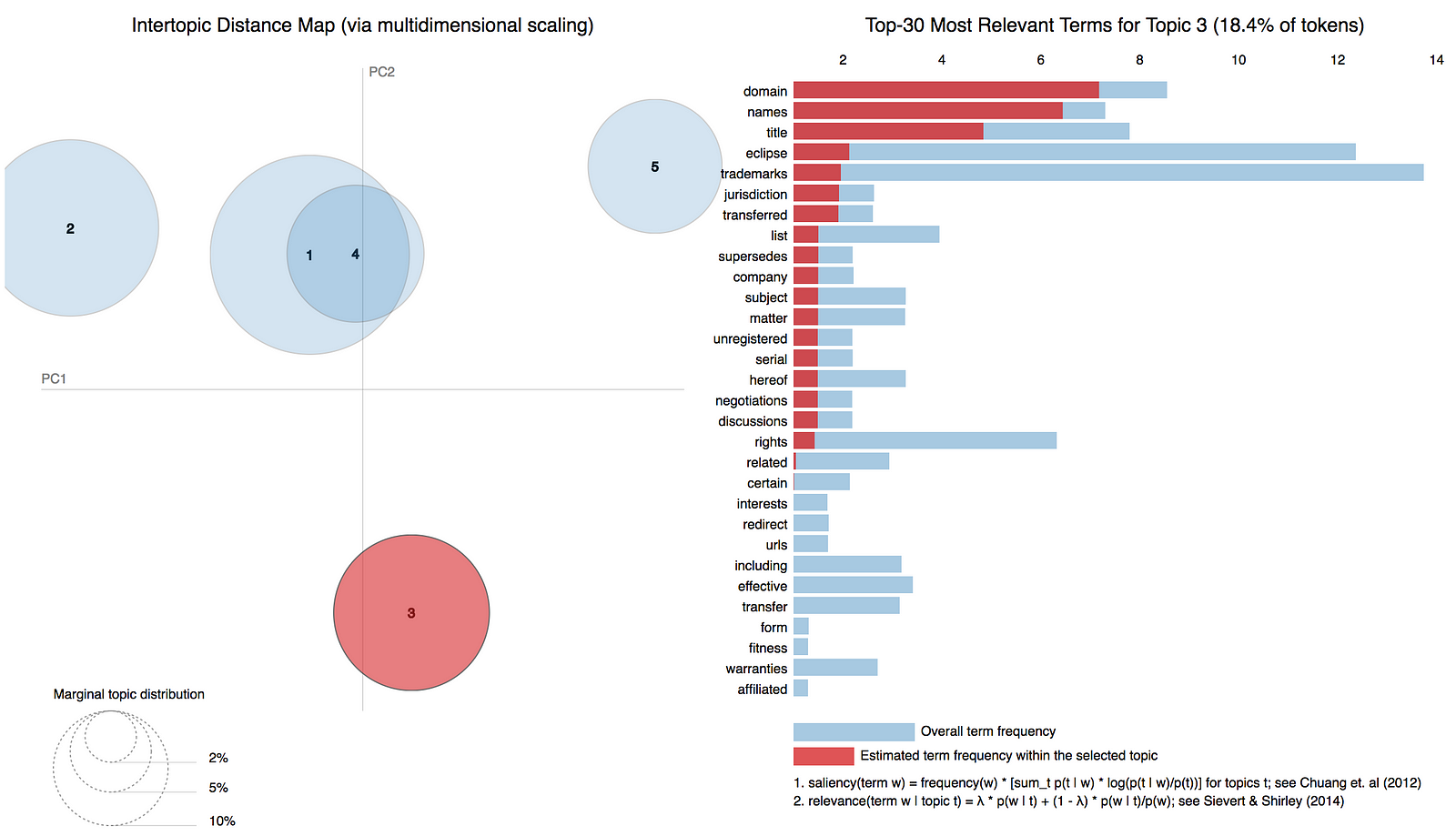
그림, 주제 3에서 가장 빈번한 단어들을 보여준다
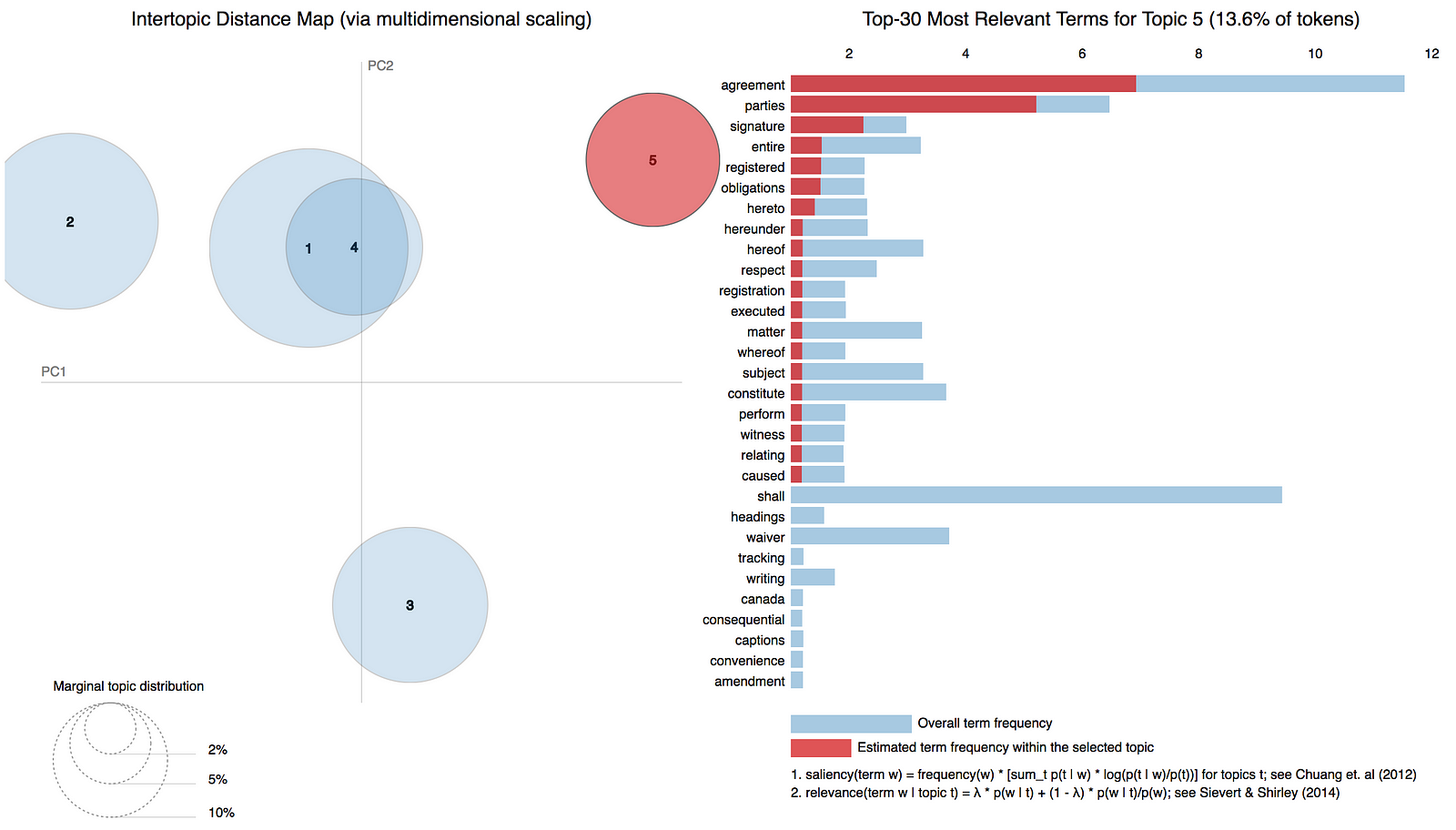
그림, 주제 5에서 가장 빈번한 단어들을 보여준다
wordcloud은 또한 전체 법률 문서가 아래 그림과 같이 문서에서 가장 반복되는 용어를 기록하기 위해 생성되었습니다. 이것은 일반적으로 다음과 같은 단어로 주제 모델링의 결과와 일치합니다. trademark, agreement,domain name, eclipse 등은 반복적이고 따라서 더 굵은 것으로 간주됩니다.

법률 문서에서 가장 많이 발생하는 단어 / 구를 보여주는 wordcloud
결론
Latent Dirichlet Allocation 모델링에서 얻은 Topics의 2, 3 및 5를 법률 문서 용으로 생성된 Word Cloud와 통합함으로써, 이 문서는 상표가 등록된 도메인 이름 이전을 위한 두 당사자 간의 간단한 법적 구속력임을 안전하게 추론할 수 있습니다.
이 프로젝트는 pdf의 문서에서 텍스트 추출에 대한 간단한 접근법을 따르며,이 프로젝트는 이미지 파일 (.jpeg .png)의 텍스트로 도달하도록 수정되어, 주제 모델링 및 요약을 문서 스냅 샷에서 수행할 수 있습니다. 이 프로젝트는 일반적으로 기계 학습이 법률 분야에서 어떻게 적용되어 손으로 주제에 대한 문서 요약을 제공할 수 있는지 보여줍니다.
이 분석에 사용된 코드(IPython 노트북)에 대한 링크는 내 github 페이지에서 찾을 수 있습니다 : https://github.com/chibueze07/Machine-Learning-In-Law/tree/master
반응형'ARCHIVE > MACHINE LEARNING' 카테고리의 다른 글
파이썬으로 하는 주식 예측 (0) 2018.03.01 파이썬으로 하는 주식분석 (0) 2018.02.23 확률 개념 설명 : 매개 변수 추정에 대한 베이지안 추론 (0) 2018.01.18 확률 개념 설명 : 최대 우도 추정 (0) 2018.01.17 확률 개념 설명 : 소개 (0) 2018.01.16