-
파이썬으로 하는 주식 예측ARCHIVE/MACHINE LEARNING 2018. 3. 1. 12:49반응형
이 문서는 영문으로된 내용을 구글 번역기를 활용하여 번역한 내용입니다.
개인적인 공부 및 추후 다시 볼 수 있도록 하기 위해 개인 블로그에 번역 내용을 옮겨 놓았습니다.
원문과 내용이 다를시 책임지지 않으며, 저작권 문제가 발생시 언제든 삭제 될 수 있습니다.원문보기 : https://towardsdatascience.com/stock-prediction-in-python-b66555171a2
파이썬으로 하는 주식 예측
진짜 파이썬을 배우면서 가짜 운명을 만들어라.
주식 시장을 예측하려고 노력하는 것은 데이터 과학자들이 물질적 이득을 추구하는 것이 아니라 도전을 위해 동기 부여를 했다는 매력적인 전망이다. 우리는 매일 시장의 오르내림 현상을 보며, 우리 또는 우리의 모델이 경영학 학위를 가지고 있는 모든 거래자들을 이기기 위해서는 어떤 패턴도 배워야 한다고 생각한다. 당연히, 내가 시계열 예측을 위해 additive model을 사용하기 시작했을 때, 시뮬레이션 자금으로 주식 시장의 입증 기반에서 방법을 테스트해 보아야 했다. 필연적으로, 나는 매일 시장을 이기려고 노력했지만 실패한 많은 다른 사람들과 합류했다. 하지만 이 과정에서 객체 지향 프로그래밍, 데이터 조작, 모델링 및 시각화 등 많은 Python을 배웠다. 나는 또한 왜 우리가 1 달러도 잃지 않고 일상적인 주식 시장에서 뛰는 것을 피해야하는지 알아 냈다 (내가 말할 수 있는 것은 긴 게임을 해야 한다는 것이다)!
하루 대 30년 : 돈을 어디에 넣을 것인가? 우리가 즉각적인 성공을 경험하지 못할 때 - 데이터 과학뿐만 아니라 어떤 작업에서도 - 우리는 세 가지 옵션을 가지고 있다 :
- 우리가 성공한 것처럼 보이도록 결과를 조정한다.
- 아무도 눈치채지 못하게 결과를 숨긴다.
- 다른 사람들(그리고 우리 자신)이 일을 더 잘할 수 있도록 우리의 모든 결과와 방법을 보여준다.
세번째 옵션은 개인 및 커뮤니티 수준에서 가장 좋은 선택이지만 구현하는 데 가장 용기가 필요하다. 내 모델이 꽤 많은 수익을 낼 수 있을 때 선택적으로 범위를 선택할 수도 있고, 아니면 몇시간씩 일을 하지 않은 척 할 수도 있다. 그건 꽤 순진한 것 같다! 우리는 성공을 증진시키기 보다는 반복적으로 실패하고 배우는 것으로 나아간다. 또한, 어려운 작업을 위해 작성된 파이썬 코드는 헛되이 쓰여진 파이썬 코드가 아니다!
이 포스트는 내가 Python으로 개발한 "주식 탐색기"툴인 Stocker의 예측 능력을 보여 준다. 이전 기사에서, 나는 분석을 위해 스톡커를 사용하는 방법을 보여 주었고, 그것을 사용하고 싶거나 그 프로젝트에 기여하고 싶은 사람들을 위해 GitHub에 완전한 코드를 사용할 수 있다.
예측을 위한 Stocker
Stocker는 주식 탐사를 위한 Python 도구이다. 필수 라이브러리가 설치되면 (문서를 확인하십시오) 스크립트와 동일한 폴더에서 Jupyter Notebook을 시작하고 Stocker 클래스를 가져올 수 있다.
이제 우리 세션에서 클래스에 접근 할 수 있다. 우리는 유효한 주식 시세 표시기 (굵게 표시됨)를 전달하여 Stocker 클래스의 객체를 생성한다.
AMZN Stocker Initialized. Data covers 1997-05-16 to 2018-01-18.`
우리는 20 년 동안의 일별 Amazon 데이터를 탐색 할 수 있다! Stocker는 Quandl 금융 라이브러리와 3000 가지가 넘는 주식으로 구성된다. 우리는
plot_stock메소드를 사용하여 주식 내역을 간단한 플롯으로 만들 수 있다 :Maximum Adj. Close = 1305.20 on 2018-01-12. Minimum Adj. Close = 1.40 on 1997-05-22. Current Adj. Close = 1293.32.
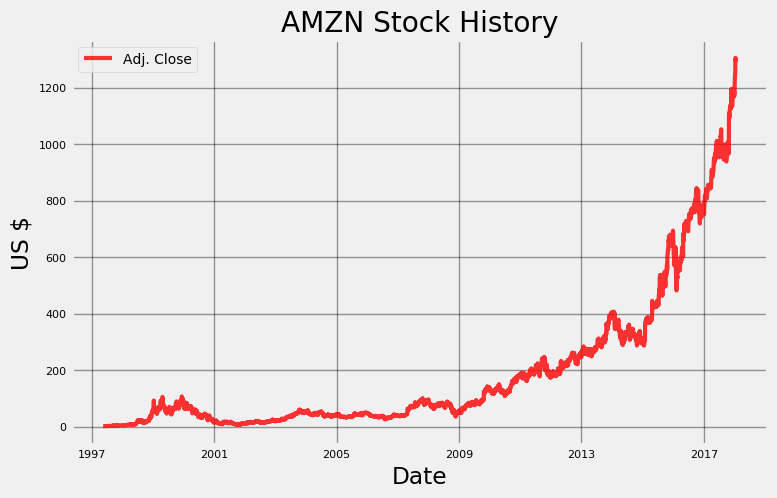
Stocker의 분석 기능을 사용하여 데이터 내의 전체 추세와 패턴을 찾을 수 있지만 향후 가격 예측에 중점을 둘 것이다. Stocker의 예측은 일별, 주별 및 월별과 같은 서로 다른 시간 척도에 따라 계절성과 함께 전체 추세의 조합으로 시계열을 고려하는 additive 모델을 사용하여 작성된다. Stocker는 additive 모델링을 위해 Facebook에서 개발 한 prophet 패키지를 사용한다. 모델 작성 및 예측은 Stocker를 사용하여 한 줄로 수행 할 수 있다.
Predicted Price on 2018-04-18 = $1336.98
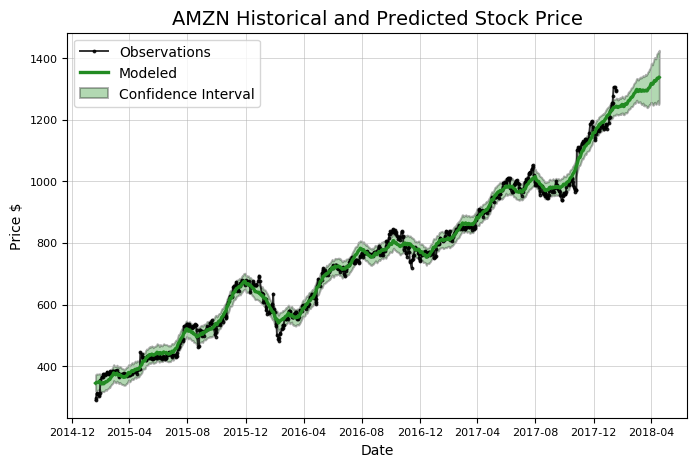
녹색 선인 예측에 신뢰 구간이 포함되어 있다는 점에 주목한다. 이것은 예측에서 모델의 불확실성을 나타낸다. 이 경우 신뢰 구간 폭은 80%로 설정되며, 이는 이 범위에 실제 시간의 80%가 포함될 것임을 의미한다. 추정치가 데이터에서 멀어질수록 불확실성이 더 커지기 때문에 신뢰 구간은 시간이 훨씬 더 길어진다. 우리는 예측할 때는 언제나 신뢰 구간을 포함해야 한다. 비록 대부분의 사람들이 미래에 대한 간단한 대답을 원하는 경향이 있지만, 우리의 예측은 우리가 불확실한 세상에 살고 있다는 것을 반영해야만 한다!
누구나 주식 시장을 예측할 수 있다. 그냥 수치만 골라 보면 알 수 있다. (내가 틀릴 수도 있지만, 월 스트리트 사람들이 하는 일이라고 확신한다.) 우리가 모델을 신뢰하기 위해서는 정확도를 평가할 필요가 있다. 모델 정확도를 평가하기 위해서는 Stocker에 여러가지 방법이 있다.
예측 평가
정확도를 계산하려면 테스트 세트와 교육 세트가 필요하다. 테스트 세트에 대한 답변 (실제 주가)을 알아야하므로 지난 1 년간의 과거 데이터 (이 경우에는 2017)를 사용하게 된다. 교육을 할 때 모델에 테스트 세트에 대한 응답을 표시하지 않으므로 테스트 기간 (2014-2016) 이전에 3 년간의 데이터를 사용한다. 감독 학습의 기본 아이디어는 훈련 세트의 데이터에서 패턴과 관계를 학습 한 다음 시험 데이터를 위해 정확하게 재현 할 수 있다는 것이다.
우리는 정확도를 계량화할 필요가 있다. 그래서 우리는 테스트 세트와 실제 값에 대한 예측을 사용하고 테스트와 교육 세트의 평균 달러 오차, 우리가 가격 변화의 방향을 정확하게 예측한 시간의 비율, 그리고 시간의 비율을 포함한 측정 기준을 계산한다. 이러한 모든 계산은 Stocker가 자동으로 수행한다.
Prediction Range: 2017-01-18 to 2018-01-18.
Predicted price on 2018-01-17 = $814.77. Actual price on 2018-01-17 = $1295.00.
Average Absolute Error on Training Data = $18.21. Average Absolute Error on Testing Data = $183.86.
When the model predicted an increase, the price increased 57.66% of the time. When the model predicted a decrease, the price decreased 44.64% of the time.
The actual value was within the 80% confidence interval 20.00% of the time.
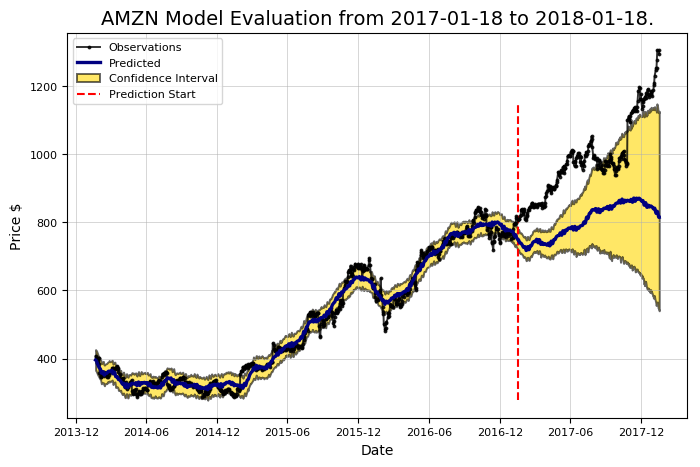
이건 최악의 통계다! 동전을 던지는 게 나았을 거다. 만약 우리가 이것을 투자에 사용한다면, 복권 같은 합리적인 것을 사는 것이 더 나을 것이다. 하지만 아직 모델에 대한 포기는 하지 않는다. 우리는 보통 첫 번째 모델이 다소 나쁘기를 기대한다. 왜냐하면 우리는 기본 설정 (과도 매개 변수라고 함)을 사용하기 때문이다. 만약 초기 시도가 성공하지 못한다면, 우리는 더 나은 모델로 만들 수 있다. Prophet 모델에는 여러 가지 설정이 있으며, 가장 중요한 것은 모델이 데이터 추세의 변화에 따라 배치하는 가중치의 양을 제어하는 변경 점 이전 스케일이다.
변경점 사전 선택
변화점은 시계열이 증가하는 것에서 감소하는 것 또는 천천히 증가하는 것에서 점점 더 빠르게 증가하는 것 (또는 그 반대)을 나타낸다. 시계열의 비율이 가장 큰 장소에서 발생한다. 이전 척도는 모델의 변경점에 주어진 강조의 양을 나타낸다. 이것은 overfitting 대 underfitting (편향 대 분산 트레이드 오프라고도 함)을 제어하는 데 사용된다.
이전보다 높은 경우 변경점에 더 많은 무게와 보다 유연한 적합성을 가진 모델을 만든다. 모델이 교육 데이터를 밀접하게 유지하고 새로운 테스트 데이터를 일반화할 수 없으므로 overfitting이 발생할 수 있다. 이전을 낮추면 반대 문제를 일으킬 수 있는 모델 유연성이 감소한다. 이는 모델이 교육 데이터를 충분히 밀접하게 따르지 않고 기본 패턴을 학습하지 못할 때 발생한다. 올바른 균형을 이루기 위한 적절한 설정을 찾는 것은 이론보다는 공학의 문제이며, 여기서 우리는 경험적 결과에 의존해야 한다. Stocker 클래스에는 시각적으로나 정량적으로 적절한 사전을 선택하는 두 가지 방법이 있다. 우리는 그래픽 방법으로 시작할 수 있다 :
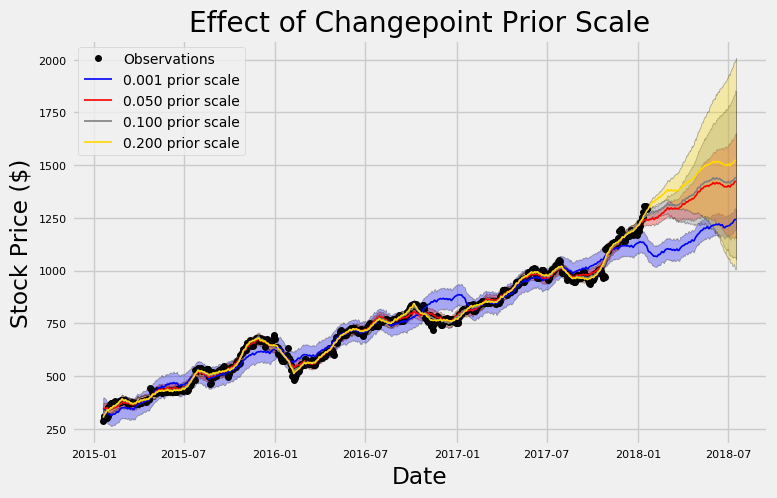
여기서 우리는 3년간의 데이터를 훈련하고 6개월 동안의 예측을 보여준다. 우리는 단지 이전의 변화점의 역할을 이해하려고하기 때문에 여기서 예측을 계량화하지 않는다. 이 그래프는 underfitting 대 overfitting을 잘 보여주는 것입니다! 가장 낮은 이전의 파란색 선은 교육 데이터, 검은 색인 관측치를 매우 가깝게 따르지 않는다. 그것은 일종의 자체적인 일을 하고 데이터의 일반적인 주변을 통과하는 경로를 선택한다. 대조적으로, 가장 높은 이전의 노란색 선은 가능한한 가까이에서 교육 관찰을 유지한다. 이전 변경 지점의 기본값은 0.05이며 두 극단 사이의 어딘가에 있다.
또한 이전의 불확실성 (음영 처리 된 간격)의 차이에 주목한다. 가장 낮은 선행 값은 훈련 데이터에서 가장 큰 불확실성을 가지지만 시험 데이터에서 가장 작은 불확실성을 가진다. 이와는 대조적으로, 가장 높은 선행 수준은 훈련 데이터에 대한 가장 작은 불확실성을 가지고 있지만 시험 데이터에 대한 가장 큰 불확실성을 가지고 있다. 훈련 데이터는 각 관측 결과를 면밀히 따르기 때문에, 앞의 내용이 높을수록, 교육 데이터에 대한 신뢰도가 높아진다. 그러나 테스트 데이터의 경우, overfitting 모델은 고정할 데이터 포인트 없이 손실된다. 주식은 상당히 많은 변동성을 가지고 있기 때문에 우리는 모델이 가능한한 많은 패턴을 포착할 수 있도록 기본값보다 더 유연한 모델을 원할 것이다.
이제 우리는 이전의 효과에 대한 아이디어를 가지고 있으므로 교육 및 검증 세트를 사용하여 다른 값을 수치 적으로 평가할 수 있다.
Validation Range 2016-01-04 to 2017-01-03.
cps train_err train_range test_err test_range 0.001 44.507495 152.673436 149.443609 153.341861 0.050 11.207666 35.840138 151.735924 141.033870 0.100 10.717128 34.537544 153.260198 166.390896 0.200 9.653979 31.735506 129.227310 342.205583
여기서는 검증 데이터가 테스트 데이터와 동일하지 않도록 주의해야 한다. 이 경우 테스트 데이터에 가장 적합한 모델을 만들지 만 테스트 데이터가 너무 많아 모델이 실제 데이터로 변환 될 수 없다. 데이터 과학에서 일반적으로 행해지는 것처럼, 우리는 교육 세트(2013~2015년), 검증 세트(2016년), 테스트 세트(2017년)의 세 가지 데이터 세트를 사용하고 있다.
우리는 훈련 오류, 훈련 범위 (신뢰 구간), 테스팅 오류 및 테스팅 범위 (신뢰 구간)와 같은 4 가지 지표를 달러 단위의 모든 값으로 평가했다. 우리가 그래프에서 보았 듯이, 선행도가 높을수록, 훈련 오류가 낮아지고 훈련 데이터의 불확실성이 낮아진다. 또한 이전보다 높은 선행은 테스트 오류를 줄임으로써 데이터와 밀접하게 맞는 것이 주식에 대한 좋은 생각이라는 직감을 뒷받침한다. 테스트 세트에 대한 정확도를 높이기 위해 이전 데이터가 증가함에 따라 테스트 데이터에 대한 불확실성 범위가 커진다.
Stocker 사전 유효성 검사에는 다음 점을 보여주는 두 개의 그림도 표시된다.
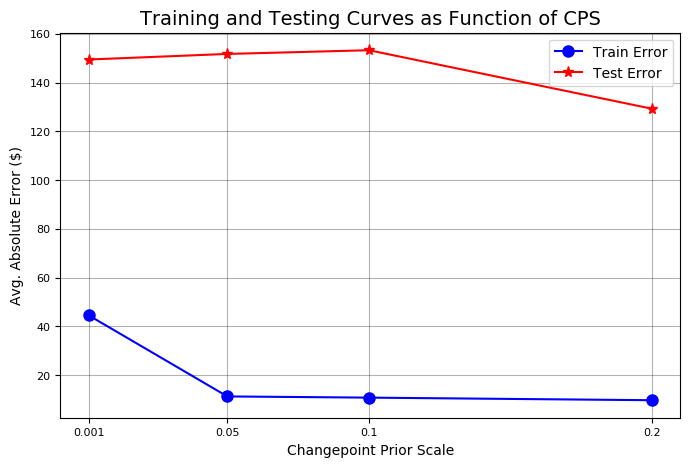
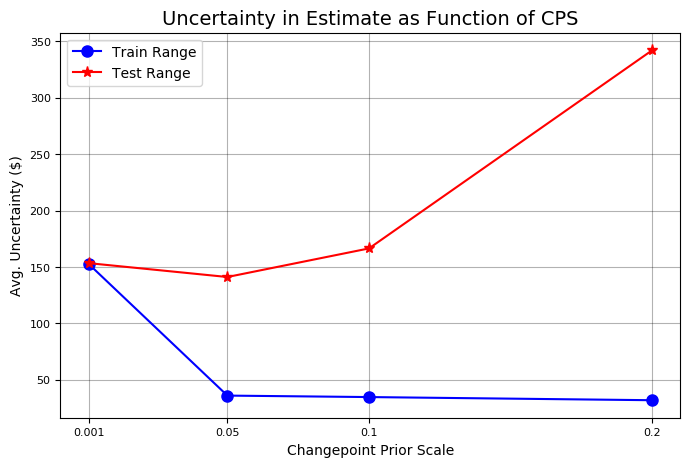
변화점 이전 척도에 대한 정확도 곡선 및 불확실성에 대한 교육 및 테스트 가장 높은 이전의 시험 결과가 가장 낮은 시험 오류를 발생시켰으므로, 우리는 더 나은 성과를 얻기 위해 이전보다 더 높은 점수를 얻으려고 노력해야 한다. 유효성 검사 메서드에 추가 값을 전달하여 검색을 구체화 할 수 있다.
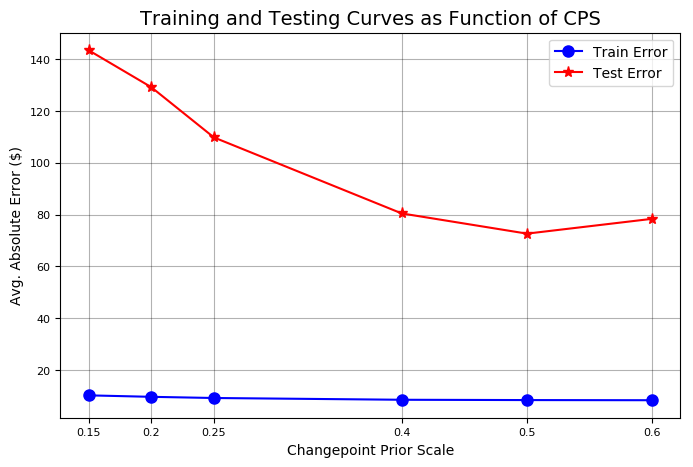
개선 된 교육 및 테스트 곡선 테스트 집합 오류는 0.5 이전에 최소화된다. 우리는 Stocker 객체의 changepoint prior 속성을 적절하게 설정한다.
우리가 볼 수있는 패턴이나 모델이 사용하는 데이터의 훈련 년수와 같이 조정할 수있는 모델의 다른 설정이 있다. 최상의 조합을 찾는 것은 단순히 여러 가지 값으로 위의 절차를 반복해야 한다. 언제든지 설정을 사용하자!
정제된 모델 평가
이제 모델이 최적화 되었으므로 다시 평가할 수 있다.
Prediction Range: 2017-01-18 to 2018-01-18.
Predicted price on 2018-01-17 = $1164.10. Actual price on 2018-01-17 = $1295.00.
Average Absolute Error on Training Data = $10.22. Average Absolute Error on Testing Data = $101.19.
When the model predicted an increase, the price increased 57.99% of the time. When the model predicted a decrease, the price decreased 46.25% of the time.
The actual value was within the 80% confidence interval 95.20% of the time.
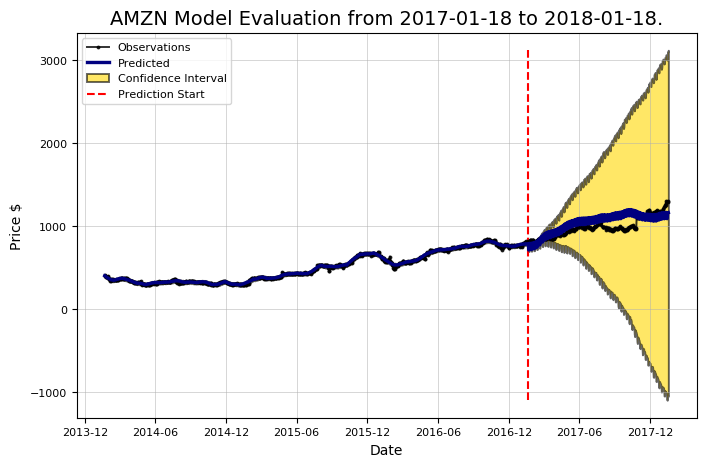
더 좋아 보인다! 이것은 모델 최적화의 중요성을 보여준다. 기본값을 사용하면 합당한 첫 번째 추측을 얻을 수 있지만 밸런스 및 페이드 조정을 통해 스테레오 사운드를 최적화하는 것처럼 오래된 모델의 "설정"을 사용하고 있는지 확인해야 한다 (오래된 레퍼런스를 유감스럽게 생각한다).
주식 시장에서 실행하기
예측을하는 것은 흥미로운 일이지만 실제 재미있는 점은 이러한 예측이 실제 시장에서 얼마나 잘 실행되는지를 파악하는 것이다.
evaluate_prediction메소드를 사용하여 평가 기간 동안 모델을 사용하여 주식 시장에서 "실행" 할 수 있다. 우리는 우리 모델을 통해 정보를 얻은 전략을 사용하여 전체 기간 동안 주식을 사거나 보유하는 간단한 전략과 비교할 수 있다.우리의 전략 규칙은 간단하다.
- 매일 모델은 주식이 증가할 것으로 예측하고, 우리는 하루가 시작될 때 주식을 구입하고 하루가 끝날 때 판매합니다. 모델이 가격 하락을 예측할 때, 우리는 어떤 주식도 사지 않는다.
- 우리가 주식을 사고 하루 동안 가격이 상승하면, 우리는 우리가 구입한 주식의 수를 증가시킨다.
- 우리가 주식을 사고 가격이 하락하면, 우리는 주식의 수를 감소 시킨다.
우리는 2017 년의 전체 평가 기간 동안 매일 이 작업을 수행한다. 실행하려면 메서드 호출에 공유 수를 추가한다. Stocker는 전략이 숫자와 그래프에서 어떻게 수행되었는지 알려준다.
You played the stock market in AMZN from 2017-01-18 to 2018-01-18 with 1000 shares.
When the model predicted an increase, the price increased 57.99% of the time. When the model predicted a decrease, the price decreased 46.25% of the time.
The total profit using the Prophet model = $299580.00. The Buy and Hold strategy profit = $487520.00.
Thanks for playing the stock market!
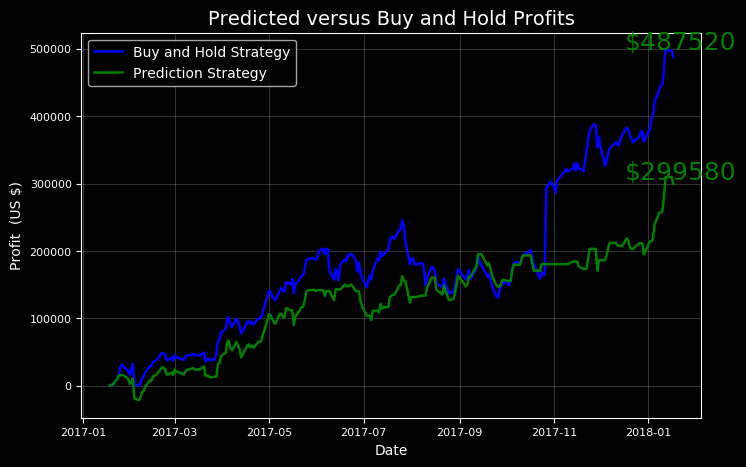
이것은 우리에게 가치있는 교훈을 보여준다 : Buy and Hold! 우리가 전략을 실행하는 데 상당한 돈을 들였을지라도, 더 나은 투자는 단순히 장기간 투자하는 것이었을 것이다.
우리는 모델 전략이 구매 및 보유 방법을 능가하는 시기가 있는지 다른 테스트 기간을 시도할 수 있다. 시장 감소를 예측할 때 게임을 하지 않기 때문에 우리의 전략은 다소 보수적이므로 주가 하락시 holding 전략보다 더 잘할 것으로 기대할 수 있다.
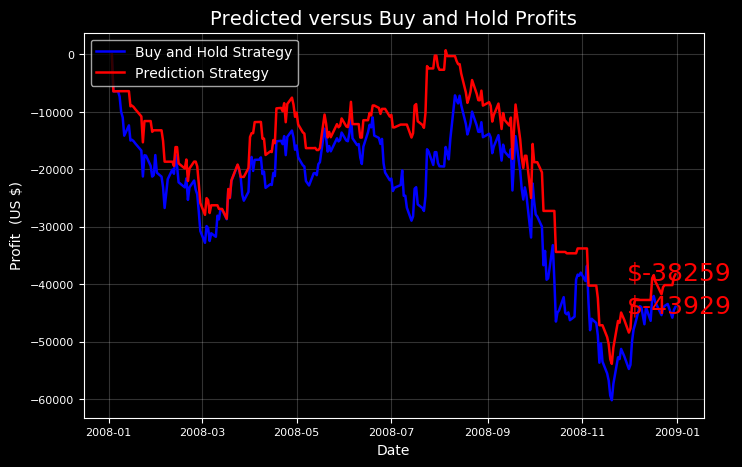
항상 가짜 돈을 가지고 놀아! 나는 우리 모델이 할 수 있다는 것을 알았다! 그러나 우리 모델은 테스트 기간을 선택하는 데 도움이 되었을 때만 시장을 이겼ek.
미래 예측
이제 우리는 괜찮은 모델을 가지고 있다는 것에 만족하고, 우리는
dervide_future()메서드를 사용하여 미래의 예측을 할 수 있다.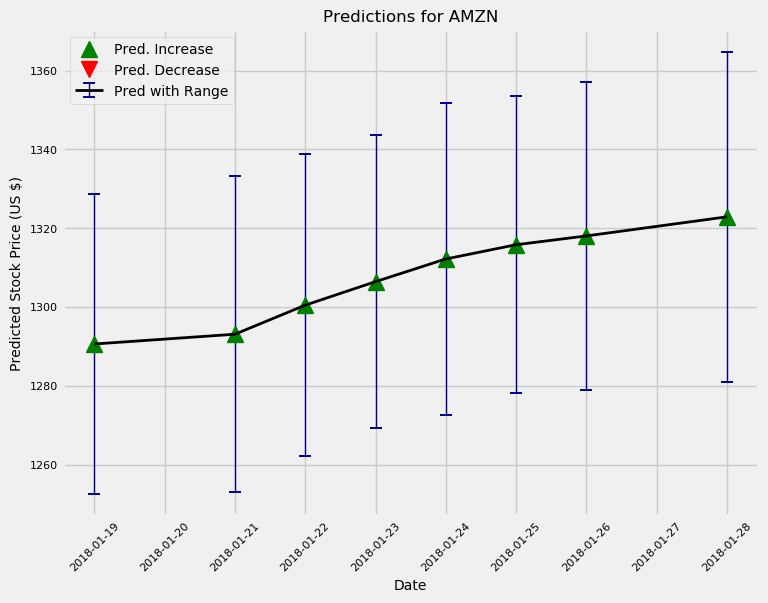
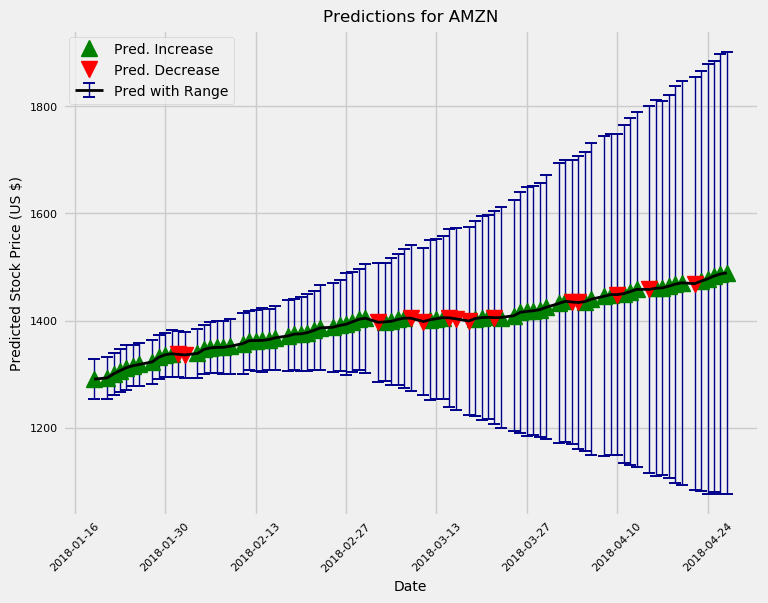
다음 10일과 100일 동안의 예측 이 모델은 대부분의 "전문가"와 마찬가지로 아마존에대해 전반적으로 낙관적이다. 또한 불확실성은 예상대로 예측을 내리는 시간이 갈수록 커졌다. 실제로 이 모델을 적극적으로 사용하여 거래하는 경우 매일 새 모델을 교육하고 최대 하루의 예측을 수행해야 한다.
Stocker 로 부자가 될 수는 없지만, 그 이점은 최종 결과가 아니라 개발 과정에 있다! 우리가 시도 할 때까지 우리가 문제를 해결할 수 있는지 실제로 알 수는 없지만 전혀 시도하지 않은 것보다 시도하고 실패하는 것이 더 낫다! 코드를 체크 아웃하거나 stocker를 사용하고자하는 사람은 GitHub에서 사용할 수 있다.
언제나처럼, 나는 피드백과 건설적인 비판을 즐긴다. 트위터 @koehrsen_will에서 연락 할 수 있다.
반응형'ARCHIVE > MACHINE LEARNING' 카테고리의 다른 글
Random Forest in Python (0) 2018.03.15 간단하게 설명한 Random Forest (0) 2018.03.03 파이썬으로 하는 주식분석 (0) 2018.02.23 법률문서의 주제 모델링과 요약을 위한 NLP (0) 2018.02.02 확률 개념 설명 : 매개 변수 추정에 대한 베이지안 추론 (0) 2018.01.18