-
Random Forest in PythonARCHIVE/MACHINE LEARNING 2018. 3. 15. 07:11반응형
이 문서는 영문으로된 내용을 구글 번역기를 활용하여 번역한 내용입니다.
개인적인 공부 및 추후 다시 볼 수 있도록 하기 위해 개인 블로그에 번역 내용을 옮겨 놓았습니다.
원문과 내용이 다를시 책임지지 않으며, 저작권 문제가 발생시 언제든 삭제 될 수 있습니다.원문보기 : https://towardsdatascience.com/random-forest-in-python-24d0893d51c0
Random Forest in Python
실용적 종단 간 학습 사례
머신러닝에 뛰어들 때가 이렇게 좋았던 적은 없었다. 온라인에서 사용할 수 있는 학습 리소스와 상상할 수 있는 알고리즘의 구현 및 AWS와 같은 클라우드 서비스를 통한 컴퓨팅 성능의 저렴한 가용성을 갖춘 무료 오픈 소스 도구를 사용하면 머신러닝은 진정으로 인터넷에 의해 민주화된 분야입니다. 노트북에 접속할 수 있고 학습하려는 의지가 있는 사람이라면 누구나 최첨단 알고리즘을 몇 분 안에 시도할 수 있다. 시간을 조금 더 많이 주면 일상생활이나 직장에서 도움이 되는 실용적인 모델을 개발할 수 있다(혹은 머신러닝 분야로 전환해서 경제적 이익을 얻을 수도 있다). 이 게시물은 강력한 Random Forest 머신러닝 모델의 종단 간 구현을 안내합니다. 그것은 Random Forest에 대한 개념적 설명을 보완하기 위한 것이지만 decision tree와 Random Forest에 대한 기본 아이디어를 가지고 있는 한 완전히 읽을 수 있습니다. 후속 포스트는 여기에 구축된 모델을 개선할 수 있는 방법에 대해 자세히 설명합니다.
여기에 파이썬 코드가 있습니다. 이것은 누군가에게 친밀감을 주기 위한 것이 아니라, 오늘날 이용 가능한 자원으로 머신러닝이 얼마나 접근하기 쉬운지를 보여주기 위한 것입니다! 데이터가 있는 전체 프로젝트는 GitHub에서 사용할 수 있으며 데이터 파일과 Jupyter Notebook은 Google Drive에서 다운로드할 수 있습니다. 필요한 것은 파이썬이 설치된 노트북과 주피터 노트북을 만드는 능력입니다. (파이썬을 설치하고 주피터 노트북을 실행하려면 이 안내서를 확인합니다.). 여기서 언급된 몇 가지 필요한 머신러닝 주제가 있습니다. 나는 그것을 명확하게 하고 관심 있는 사람들을 위해 더 많은 것을 배울 수 있는 자원을 제공하려고 노력할 것입니다.
문제소개
우리가 해결해야 할 문제는 1년 동안의 과거 기상 데이터를 사용하여 우리 도시의 내일 최대 기온을 예측하는 것입니다. 나는 워싱턴주의 시애틀을 사용하고 있지만, NOAA 기후 데이터 온라인 도구를 사용하여 여러분의 도시에 대한 데이터를 자유롭게 찾을 수 있습니다. 여기서 우리는 마치 일기예보에 접근할 수 없는 것처럼 행동할 것입니다(게다가 다른 사람에게 의존하기보다는 우리 자신의 예측을 하는 것이 더 재미있습니다). 우리가 접근할 수 있는 것은 1년의 역사적인 최대 기온, 지난 이틀 동안의 기온, 그리고 날씨에 대해 항상 모든 것을 알고 있다고 주장하는 친구의 추정치입니다. 이것은 감독된 회귀 머신러닝 문제입니다. 우리가 예측하고자 하는 피쳐(도시에 대한 데이터)와 목표(온도)를 모두 가지고 있기 때문이다. 훈련하는 동안, 우리는 Random Forest 에 피쳐와 목표를 모두 부여하고 데이터와 예측을 맵핑하는 방법을 배워야 합니다. 또한 목표 값이 연속적이기 때문에 회귀 작업입니다 (분류에서 이산 클래스와 반대). 우리에게 필요한 배경은 이 정도밖에 없으니까, 시작합시다!
로드맵
우리가 바로 프로그램에 뛰어들기 전에, 우리가 방향을 잡을 수 있게 도와줄 간단한 가이드를 준비해야 합니다. 다음 단계는 문제와 모델을 염두에 둔 모든 머신러닝 워크 플로우의 기반이 됩니다.
- 질문을 말하고 필요한 데이터를 결정합니다.
- 액세스 가능한 형식으로 데이터를 획득합니다.
- 필요에 따라 누락된 데이터 포인트/변형을 확인하고 수정합니다.
- 머신러닝 모델에 대한 데이터를 준비합니다.
- 초과하려는 기준선 모형을 설정합니다.
- 교육 데이터에 대해 모델을 교육합니다.
- 테스트 데이터에 대한 예측을 수행합니다.
- 예측을 알려진 테스트 세트 대상과 비교하고 성능 메트릭을 계산합니다.
- 성능이 만족스럽지 않으면 모델을 조정하거나 더 많은 데이터를 얻거나 다른 모델링 기술을 시도합니다.
- 모형을 해석하고 결과를 시각적으로나 수치적으로 보고합니다.
1단계는 이미 체크아웃되었습니다! 우리는 "우리 도시의 내일 최대 기온을 예측할 수 있습니까?"라는 질문을 가지고 있으며, 지난 1년 동안 워싱턴주 시애틀에서 역사적인 최대 기온에 액세스 할 수 있음을 알고 있습니다.
데이터 획득
먼저, 우리는 약간의 데이터가 필요합니다. 현실적인 예를 사용하기 위해 NOAA 기후 데이터 온라인 도구를 사용하여 2016 년부터 워싱턴 시애틀의 날씨 데이터를 검색했습니다. 일반적으로 데이터 분석에 소요되는 시간의 약 80% 는 데이터를 정리하고 검색하는 것이지만 고품질 데이터 소스를 찾아서 이 작업량을 줄일 수 있습니다. NOAA 도구는 사용이 놀라울 정도로 쉽우며, Python이나 R과 같은 언어로 구문 분석할 수 있는 깨끗한 csv 파일로 온도 데이터를 다운로드할 수 있습니다. 완전한 데이터 파일은 따라 하기를 원하는 사람들을 위해 이곳에서 다운로드할 수 있습니다.
다음 파이썬 코드는 csv 데이터에서 로드되고 데이터 구조를 표시합니다.
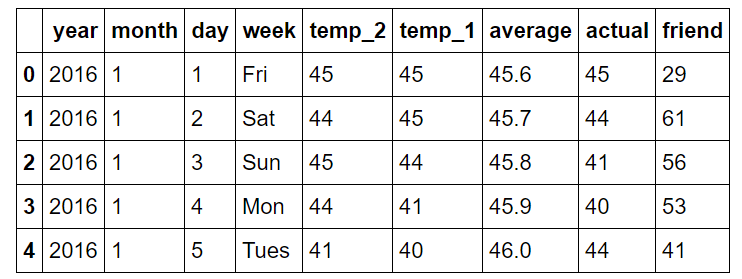
정보는 각 행이 하나의 관측치를 형성하고 열에 변수 값을 갖는 깔끔한 데이터 형식입니다.
다음은 열에 대한 설명입니다.
year : 모든 데이터 포인트에 대한 2016
month : 1 년 중 월 번호
day : 일년 중 일의 수
week : 문자열로 요일
temp_2 : 2일 전 최대 온도
temp_1: 하루 전 최대 온도
average : 과거 평균 최대 온도
actual : 최대 온도 측정
friend : 친구의 예측, 평균보다 20 낮거나 20 높은 사이의 임의의 숫자
이상 현상/누락된 데이터 식별
데이터의 차원을 보면, 단지 348개의 행만 있다는 것을 알 수 있는데, 이는 우리가 2016년이 366일이었다는 사실과 전혀 일치하지 않습니다. NOAA의 자료를 살펴보니 며칠 빠진 것이 발견되었습니다. 실제 세계에서 수집된 데이터가 완벽하지는 못하다는 것을 상기시켜줍니다. 누락된 데이터는 잘못된 데이터 또는 특이 치가 될 수 있어 분석에 영향을 줄 수 있습니다. 이 경우 누락된 데이터는 큰 영향을 미치지 않으며 데이터 품질이 좋습니다. 또한 8개의 피쳐와 하나의 대상(실제)을 나타내는 9개의 열을 볼 수 있습니다.
The shape of our features is: (348, 9)
이상 현상을 식별하기 위해 요약 통계를 신속하게 계산할 수 있습니다.
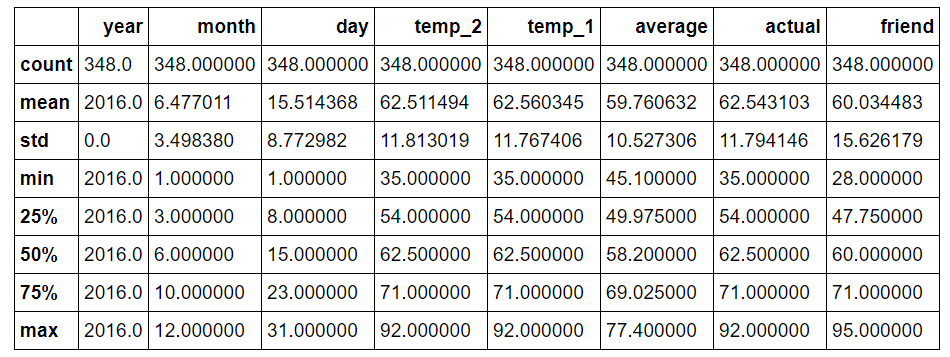
Data Summary 임의의 측정 열에 이상이 없고 0으로 나타나는 데이터 포인트는 없습니다. 데이터의 품질을 확인하는 또 다른 방법은 기본 플롯을 만드는 것입니다. 숫자보다는 그래프에서 예외를 쉽게 발견할 수 있습니다. 플롯이 파이썬이 아니기 때문에 실제 코드는 생략했습니다. 전체 구현에 대해 얼마든지 노트북을 참조하여 확인할 수 있기 때문입니다. (데이터 과학자와 마찬가지로 Stack Overflow에서 플로팅 코드를 거의 복사하고 붙여 넣었습니다).
정량적인 통계와 그래프들을 검토하면서, 우리는 데이터의 높은 품질에 자신감을 느낄 수 있습니다. 분명하게 이상한 값은 없으며, 누락된 점이 몇 개 있지만 분석에서 빗나가지 않을 것입니다.
데이터 준비
불행하게도 우리는 모델에 원시 데이터를 입력하고 대답을 반환할 수 있는 시점에 있지 않습니다 (사람들이 이 작업을 하고 있지만)! 데이터를 기계가 이해할 수 있는 용어로 바꾸려면 약간의 수정이 필요합니다. 우리는 데이터 조작을 위해, 데이터 프레임으로 알려진 구조에 의존하는 파이썬 라이브러리인 Pandas를 사용할 것입니다. 데이터 프레임은 기본적으로 행과 열이 있는 엑셀 스프레드시트와 같습니다.
데이터 준비의 정확한 단계는 사용된 모델과 수집된 데이터에 따라 다르지만 모든 머신러닝 응용 프로그램에는 약간의 데이터 조작이 필요합니다.
원-핫 인코딩
첫 번째 단계는 데이터의 원-핫 인코딩입니다. 이 프로세스는 요일과 같은 범주형 변수를 사용하여, 임의의 순서 없는 숫자로 변환합니다. 요일은 항상 사용하기 때문에 우리에게는 직관적입니다. ‘월요일’ 이란 주중의 첫날을 가리키는 것을 모르는 사람은 없지만, 기계는 이와 관련한 직관적인 지식이 없습니다. 컴퓨터가 아는 것은 숫자이고 머신러닝을 위해서는 그것을 수용해야 합니다. 우리는 단순히 요일을 숫자 1-7로 매핑할 수 있지만, 알고리즘은 더 높은 수치 값을 가진 일요일을 더 중요하게 판단할 수 있습니다. 따라서, 평일의 단일 열을 7개의 이진 데이터의 열로 변경합니다. 그림으로 그려보는 것이 이해하기 좋습니다. 하나의 원-핫 인코딩은 다음과 같습니다.
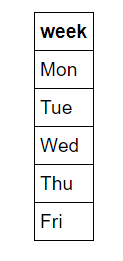
다음과 같이 변경합니다.
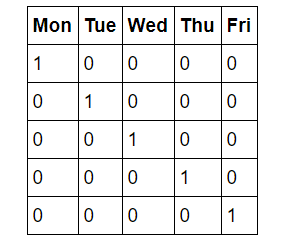
데이터가 수요일이면 수요일 열에 1이 있고 다른 모든 열에 0이 있습니다. 이 과정은 Pandas에서 한 줄로 할 수 있습니다!
원-핫 인코딩 후 데이터 스냅 샷 :

원-핫 인코딩 후 데이터 데이터의 모양은 이제 349 x 15이고 모든 열은 숫자입니다. 이것은 알고리즘이 좋아하는 방법입니다!
배열로부터 피쳐, 목표 및 데이터 변환
이제 데이터를 피쳐와 목표로 구분해야 합니다. 레이블이라고도 하는 목표는 우리가 예측하고자 하는 값입니다. 이 경우 실제 최대 온도이며, 피쳐는 모델이 예측을 위해 사용하는 모든 열입니다. 우리는 또한 알고리즘이 작동할 수 있게 Pandas 데이터 프레임을 Numpy 배열로 변환할 것입니다. (기능의 이름인 열 머리글을 나중에 시각화에 사용할 목록에 저장합니다.)
학습 및 테스트 세트
데이터 준비의 마지막 단계는 데이터를 학습 및 테스트 세트로 분할하는 것입니다. 훈련 과정에서 우리는 모델이 답을 ‘보게’ 함으로써, 이 경우는 실제 온도를 ‘보게’ 함으로써, 피쳐로부터 온도를 예측하는 방법을 배울 수 있습니다. 우리는 모든 피쳐와 목표값 사이에 어떤 관계가 있을 것으로 기대하며, 모델의 임무는 훈련 중에 이러한 관계를 배우는 것입니다. 그런 다음 모델을 평가할 때가 되면, 우리는 모델에 테스트 세트(해답이 아닌)에 피쳐만 보여줘서 목표를 예측하도록 요청합니다! 테스트 세트에 대한 실제 답변이 있기 때문에 예측값을 실제값과 비교하여 모델의 정확성을 판단할 수 있습니다. 일반적으로 모델을 훈련할 때는 데이터를 학습 및 테스트 세트로 무작위로 나눕니다 (우리가 첫 9 개월 동안의 데이터로 훈련을 한 다음 마지막 3 개월의 데이터를 예측에 사용하면 알고리즘은 마지막 3개월 동안의 데이터를 학습하지 않았기 때문에 제대로 작동하지 않습니다.) 나는
random_state를 42로 설정하면 재현 가능한 결과를 위해 분할을 실행할 때마다 결과가 동일하게 됩니다.다음 코드는 데이터 세트를 다른 단일 행으로 분할합니다.
우리는 모든 데이터의 모양을 보고 모든 것을 올바르게 했는지 확인할 수 있습니다. 학습 피쳐에는 열의 테스트 피쳐 수와 각 학습 및 테스트 피쳐 및 레이블에 일치하는 행 수와 일치하는 열 개수가 필요합니다.
모든 것이 질서 정연해 보입니다! 요약하면, 데이터를 머신러닝에 적합한 형태로 만들기 위해 우리는 다음과 같이 했습니다.
- 범주형 변수를 원-핫 인코딩했습니다.
- 데이터를 피쳐 및 레이블로 분할합니다
- 배열로 변환했습니다
- 데이터를 학습 및 테스트 세트로 분할합니다
초기 데이터 세트에 따라 특이값을 제거하고, 누락된 값을 입력하거나 임시 변수를 주기적 표현으로 변환하는 것과 같은 추가 작업이 필요할 수 있습니다. 이러한 단계는 처음에는 임의적으로 보일 수 있지만 기본 워크플로우를 얻으면 일반적으로 모든 머신러닝 문제에 대해 동일합니다. 인간이 읽을 수 있는 데이터를 머신러닝 모델이 이해할 수 있는 형태로 만드는 것이 전부입니다.
기준선을 설정합니다
예측을 하고 평가하기 전에 우리는 기준선, 즉 우리가 모델과 비교하기를 희망하는 합리적인 척도를 만들어야 합니다. 만약 우리의 모델이 기준선에서 개선되지 못한다면 그것은 실패일 것이고, 우리는 다른 모델을 시도하거나 머신러닝이 우리의 문제에 맞지 않는다는 것을 인정해야 합니다. 다른 말로 하면, 우리의 기준선은 우리가 단지 하루 동안 평균 최대 온도를 예측했을 때 생길 수 있는 오류입니다.
Average baseline error: 5.06 degrees.
이제 목표가 생겼습니다! 평균 오차 5도를 이길 수 없다면, 우리는 다시 한번 생각을 해봐야 합니다.
학습 모델
데이터 준비 작업을 모두 마친 후, 모델을 만들고 학습하는 것은 Scikit-learn을 사용하면 매우 간단합니다. 우리는 Random Forest 회귀 모델을 skicit-learn에서 가져와서 인스턴스 화하고 교육 데이터에 모델을 fit (scikit-learn에서 학습을 위한 이름) 합니다. (재현 가능한 결과를 위해 임의의 상태를 다시 설정하라). 이 전체 과정은 scikit-learn에서 겨우 세 줄에 불과합니다!
테스트 세트에서 예측하기
이제 모델은 피쳐와 대상 간의 관계를 학습하도록 훈련되었습니다. 다음 단계는 모델이 얼마나 좋은지 파악하는 것입니다! 이를 위해 우리는 테스트 피쳐에 대한 예측을 합니다 (모델은 테스트 답변을 볼 수 없습니다). 그런 다음 예측을 알려진 답변과 비교합니다. 회귀 분석을 수행할 때, 우리는 절대 오차를 반드시 사용해야 합니다. 왜냐하면 우리는 대답의 일부가 낮고 일부는 높을 것으로 예상하기 때문입니다. 우리는 평균 예측이 실제 값과 얼마나 멀리 떨어져 있는지에 관심이 있으므로 절대 값을 취합니다 (기본선을 설정할 때와 마찬가지로).
Skict-learn의 또 다른 1 행 명령은 모델 밖에서 예측을 하는 것입니다.
Mean Absolute Error: 3.83 degrees.
우리의 평균 예측치는 3.83도 정도 떨어져 있습니다. 이는 기준선보다 평균 1도 이상 향상된 것입니다. 이것이 중요하지는 않지만, 현장과 문제에 따라 회사에 수백만 달러의 영향을 줄 수 있는 기준선보다 거의 25% 나 낫습니다.
성능 메트릭을 결정합니다
우리의 예측을 고려해 볼 때, 평균 백분율 오차를 100%에서 뺀 값으로 정확도를 계산할 수 있습니다.
Accuracy: 93.99 %.
꽤 좋아 보이네요! 우리 모델은 시애틀에서 다음날의 최고 기온을 94%의 정확도로 예측하는 법을 배웠습니다.
필요한 경우 모델 개선
일반적인 머신러닝 워크 플로우에서 하이퍼 파라미터 튜닝을 시작할 때입니다. 이것은 "성능을 향상하기 위한 설정 조정"을 의미하는 복잡한 구문입니다 (설정은 학습 중에 익힌 모델 파라미터와 구별하기 위해 하이퍼 파라미터로 알려져 있습니다). 이를 수행하는 가장 일반적인 방법은 단순히 여러 설정을 사용하여 다른 여러 모델을 만들고 동일한 유효성 검사 세트로 모든 모델을 평가하고 어떤 모델이 가장 잘하는지 보는 것입니다. 물론 이것을 손으로 할 경우 지루한 과정일 것입니다. Skicit-learn에서는 이 과정을 수행하는 자동화된 방법이 있습니다. 하이퍼 파라미터 튜닝은 종종 이론 기반보다 경험적인 경우가 많기 때문에, 나는 관심 있는 사람들이 문서를 확인하고 놀기 시작하도록 권장합니다! 이 문제에 대해 94 %의 정확도는 만족스럽지만 첫 번째 모델은 생산에 필요한 모델이 거의 없음을 명심하십시오.
해석 모델 및 보고서 결과
이 시점에서 우리는 우리 모델이 훌륭하다는 것을 알지만, 블랙박스와 거의 비슷합니다. 우리는 훈련을 위해 Numpy 배열을 제공하고, 예측을 하고, 예측을 평가하고, 합리적인지 확인합니다. 문제는 이 모델이 어떻게 값에 도달하는가입니다. Random Forest는 두 가지 접근 방법이 있습니다. 첫째, Forest에 있는 단일 tree를 볼 수 있으며 둘째, 설명 변수의 피쳐를 볼 수 있습니다.
단일 결정 트리 시각화
Skicit-learn에서 Random Forest 구현의 가장 멋진 부분 중 하나는 실제로 Forest 의 모든 Tree를 조사할 수 있다는 것입니다. Tree 하나를 선택하고 전체 Tree를 이미지로 저장합니다.
다음 코드는 Forest에서 하나의 Tree를 가져 와서 이미지로 저장합니다.
다음과 같이 보여집니다.
Single Full Decision Tree in Forest 와! 15개의 층을 가진 꽤 넓은 Tree처럼 보입니다(실제로 이것은 내가 본 몇몇 Tree에 비해 꽤 작은 나무입니다.). 직접 다운로드해서 자세히 조사해 보실 수는 있지만, 일을 더 쉽게 하기 위해 Tree의 깊이를 제한해서 이해할 수 있는 이미지를 만들겠습니다.
여기 레이블로 주석이 달린 축소된 Tree가 있습니다
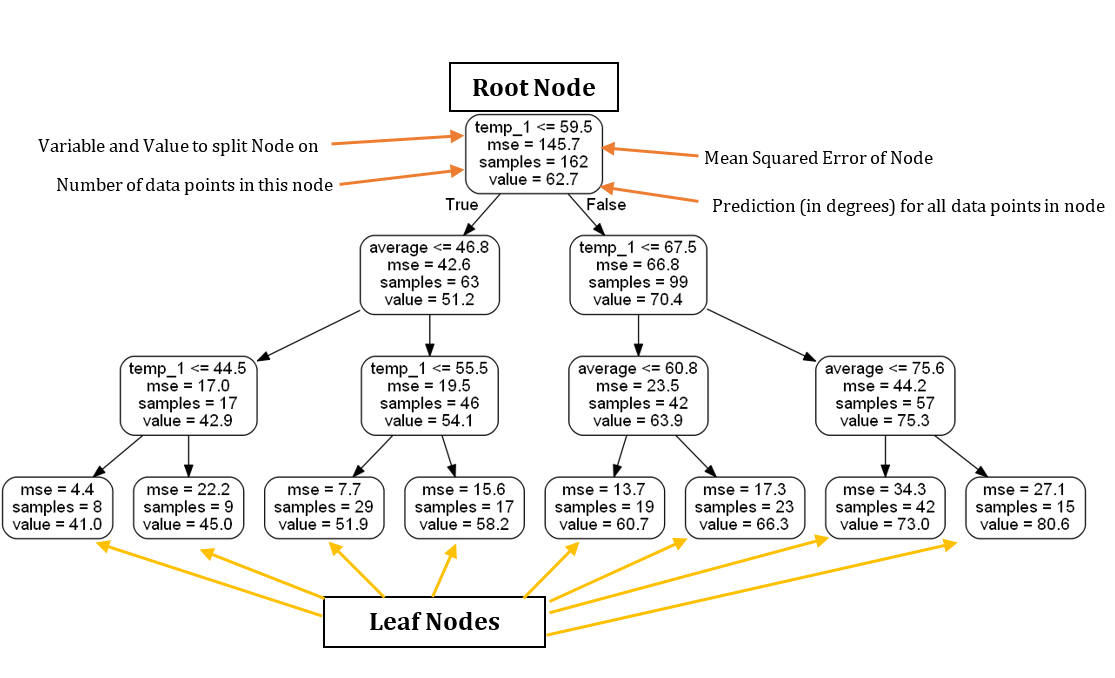
이 Tree를 기반으로 새로운 데이터 포인트에 대한 예측을 할 수 있습니다. 2017년 12월 27일 수요일에 대한 예측을 예로 들어 보겠습니다. (실제) 변수는 temp_2 = 39, temp_1 = 35, 평균 = 44, 친구 = 30입니다. 우리는 루트 노드에서 시작하고 첫 번째 대답은 temp_1 ≤ 59.5이므로 참입니다. 왼쪽으로 이동하면 두 번째 질문을 확인합니다. 평균 ≤ 46.8 이므로 참이라서, 왼쪽으로 이동합니다. temp_1 ≤ 44.5이므로 참이기 때문에 왼쪽으로 이동합니다. 최대 온도에 대한 추정치는 리프 노드의 값으로 표시된 41.0도입니다. 흥미로운 관찰은 루트 노드에서 261 개의 교육 데이터 포인트가 있음에도 불구하고 162 개의 샘플만 있다는 것입니다. 이는 포리스트의 각 Tree가 데이터 포인트의 무작위 하위 집합에서 교체 (부트 스트랩 집계의 약자인 bagging이라고 합니다.) 되도록 훈련되었기 때문입니다. (Forest를 만들 때 bootstrap = False로 설정하면 모든 데이터 요소를 사용할 수 있습니다.). 데이터 포인트의 무작위 샘플링과 Tree의 각 노드에서 피쳐의 하위 집합을 무작위로 샘플링하는 것이 모델을 'Random' forest라고 부르는 이유입니다.
게다가, 우리의 Tree에는 실제로 예측을 하기 위해 사용한 변수가 두 개뿐입니다! 이 특정 의사 결정 트리에 따르면 나머지 기능은 중요하지 않습니다. 내일의 최고 기온을 예측하는데 1년 중 몇 월인지, 무슨 요일인지, 그리고 친구는 어떻게 예측했는지는 전혀 쓸모가 없습니다! 우리의 단순한 Tree에 따르면 유일하게 중요한 정보는 하루 전의 온도와 그동안의 평균입니다. Tree를 시각화하면 문제에 대한 도메인 지식이 증가했으며 예측을 요청받을 때 어떤 데이터를 찾아야 하는지 알 수 있습니다!
변수의 중요성
Random Forest 전체에서 모든 변수의 유용성을 정량화하려면 변수의 상대적 중요성을 보면 됩니다. Skicit-learn에서 반환된 중요성은 특정 변수를 포함하여 예측을 얼마나 향상하는지 나타냅니다. 중요성의 실제 계산은 이 게시물의 범위를 벗어나지만 숫자를 사용하여 변수를 상대 비교할 수 있습니다.
여기에 있는 코드는 파이썬 언어의 여러 가지 트릭, 즉 포괄적인 목록, zip, 정렬 및 인수 풀기를 이용합니다. 지금은 이런 것들을 이해하는 것이 중요하지 않지만, 파이썬에 능숙해지고 싶다면, 이것들을 이해해야 합니다!
Variable: temp_1 Importance: 0.7 Variable: average Importance: 0.19 Variable: day Importance: 0.03 Variable: temp_2 Importance: 0.02 Variable: friend Importance: 0.02 Variable: month Importance: 0.01 Variable: year Importance: 0.0 Variable: week_Fri Importance: 0.0 Variable: week_Mon Importance: 0.0 Variable: week_Sat Importance: 0.0 Variable: week_Sun Importance: 0.0 Variable: week_Thurs Importance: 0.0 Variable: week_Tues Importance: 0.0 Variable: week_Wed Importance: 0.0
목록의 맨 위에는 전날의 최대 온도인 temp_1이 있습니다. 이것은 하루 동안 최대 온도의 가장 좋은 예측인자가 전날의 최대 온도라는 것을 알려줍니다. 이것은 직관적인 발견입니다. 두 번째로 중요한 요소는 그동안의 평균 최대 온도이며 그리 놀라운 것은 아닙니다. 친구의 예측값과 이틀 전의 하루, 연도, 월, 요일이 예측에 도움이 되지 않는 것으로 나타났습니다. 이것은 우리가 그 주의 요일이 날씨와 아무런 관계가 없어서 최고 기온의 예측 변수가 될 것으로 기대하지 않았기 때문에 타당합니다. 더욱이, 연도는 모든 데이터에서 동일하므로 최대 온도를 예측할 수 있는 정보가 없습니다.
미래에 구현할 모델에서는 중요도와 성능에 영향을 미치지 않는 변수를 제거할 수 있습니다. 추가로, 다른 모델(예:support vector machine)을 사용하고 있다면, Random Forest 의 중요성을 선택 방법으로 사용할 수 있습니다. 가장 중요한 두 변수, 즉 하루 전 최대 온도와 과거 평균값만 사용하여 신속하게 Random Forest를 만들어 성능을 비교해 보겠습니다.
Mean Absolute Error: 3.9 degrees. Accuracy: 93.8 %.
이것은 우리에게 정확한 예측을 하기 위해 수집한 모든 데이터가 실제로 필요하지 않다는 것을 말해줍니다! 이 모델을 계속 사용한다면 두 변수만 수집해도 동일한 성능을 얻을 수 있습니다. 생산 환경에서는 더 많은 정보를 얻는 데 필요한 추가 시간과 정확도의 감소를 비교해야 합니다. 성능과 비용 사이의 올바른 균형을 찾는 방법을 아는 것은 기계 학습 엔지니어에게 필수적인 기술이며 궁극적으로 해결해야 할 문제에 달려 있습니다!
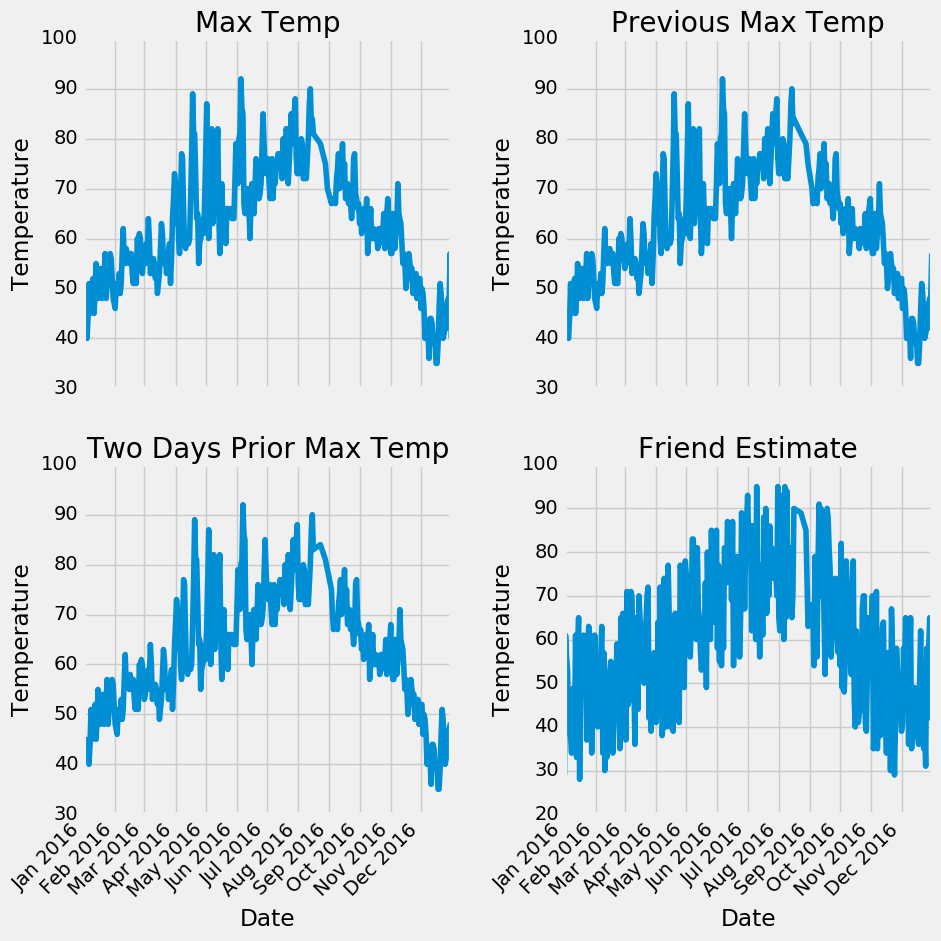
이 시점에서 우리는 감독된 회귀 문제에 대한 Random Forest의 기본 구현에 대해 알아야 할 거의 모든 것을 다루었습니다. 우리의 모델이 1년의 과거 데이터로부터 94퍼센트의 정확도로 내일의 최고 기온을 예측할 수 있다고 확신할 수 있습니다. 이 예제를 자유롭게 사용하거나 원하는 데이터 집합에서 모델을 사용하십시오. 이제 몇 가지 시각화를 통해 이 게시물을 마무리합니다. 제가 데이터 과학에서 가장 좋아하는 두 부분은 그래프와 모델링이므로 차트를 만들어야 합니다! 차트는 보기에 즐겁고, 우리가 빨리 검토할 수 있는 이미지로 많은 숫자를 압축하기 때문에 모델을 진단하는 데 도움이 됩니다.
시각화
첫 번째 차트는 변수의 상대적 중요성에서의 불균형을 설명하기 위해 피쳐의 중요성을 보여주는 간단한 막대 그림입니다. 파이썬에서의 플롯팅은 직관적이지 않습니다. 스택 오버플로우에서 그래프를 만들 때 필요한 거의 모든 것을 찾아볼 수 있습니다. 코드가 제대로 이해되지 않는다고 걱정하지 마세요. 때로는 원하는 결과를 얻기 위해 코드를 충분히 이해할 필요가 없습니다!
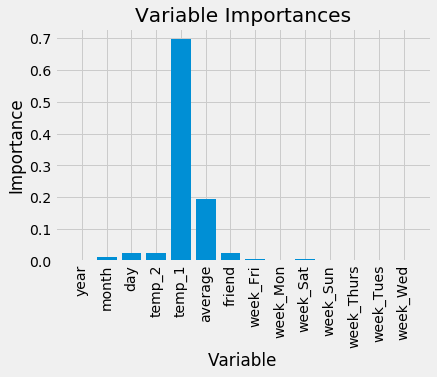
다음으로, 전체 데이터 집합에서 예측값을 강조하여 표시할 수 있습니다. 이를 위해서는 약간의 데이터 조작이 필요하지만 그리 어렵지는 않습니다. 이 그래프를 사용하여 데이터 또는 예측에 특이치가 있는지 여부를 확인할 수 있습니다.
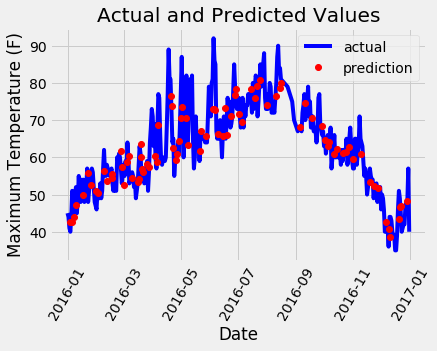
멋진 그래프를 위해 조금 작업했습니다! 우리가 수정해야 할 만큼 눈에 띄는 특이치를 가지고 있는 것처럼 보이지 않습니다. 모델을 더 진단하기 위해 오류를 표시하여 모델이 과도하게 예측하거나 예측하지 못하는 경향이 있는지 확인할 수 있으며, 오류가 정규 분포인지 확인할 수도 있습니다. 하지만 나는 하루 전의 실제 값, 온도, 과거 평균, 친구의 예측을 보여주는 마지막 차트를 만들 것입니다. 이를 통해 유용한 변수와 별로 도움이 되지 않는 변수의 차이를 확인할 수 있습니다.
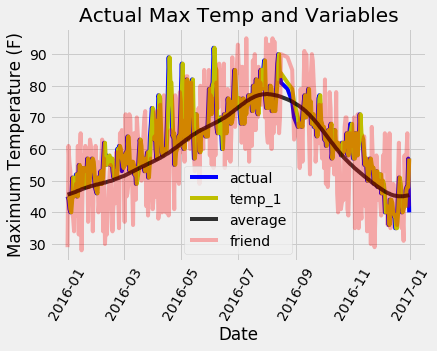
모든 선을 파악하는 것은 다소 어렵지만, 하루 전의 최대 온도와 과거의 최대 온도가 최대 온도를 예측하는 데 도움이 되는 이유를 알 수 있습니다. (아직 친구를 포기하지 마세요. 하지만 그의 견적에 너무 많은 무게를 두지도 마세요!) 이와 같은 그래프는 종종 미리 작성하는 데 도움이 되므로 포함할 변수를 선택할 수 있지만 진단을 위해 사용할 수도 있습니다. 안스콤베의 4중주곡에서와 마찬가지로 그래프는 양적 숫자보다 더 많이 드러나는 경우가 많으며, 어떤 기계 학습 워크플로우든 그 일부가 되어야 합니다.
결론
이러한 그래프를 통해 우리는 전체 종단 간 머신러닝 예제를 완성했습니다! 이 시점에서 모델을 개선하고 싶다면, 다른 하이퍼 파라미터 (설정)를 사용하여 다른 알고리즘을 시도하거나, 가장 좋은 방식의 접근을 통해 더 많은 데이터를 수집할 수 있습니다! 모델의 성능은 학습할 수 있는 유효한 데이터의 양에 정비례하며, 교육에 매우 제한된 양의 정보를 사용했습니다. 나는 누구든지 이 모델을 개선하고 결과를 공유하길 바랍니다. 여기서 수많은 온라인(무료) 리소스를 이용해 Random Forest 이론과 응용 프로그램을 더 많이 알아볼 수 있습니다. 머신러닝 모델의 이론과 파이썬 구현을 모두 다루는 책을 찾는 사람들에게는 Scikit-Learn과 Tensorflow를 이용한 Hands-On Machine Learning을 강력히 권장합니다. 더욱이, 나는 그것을 통과한 모든 사람들이 머신러닝에 접근하고, 도움이 되는 머신러닝 커뮤니티에 참여할 준비가 되어 있기를 바랍니다.
언제나처럼, 저는 피드백과 건설적인 비판을 환영합니다! 제 이메일은 wjk68@case.edu입니다.
반응형'ARCHIVE > MACHINE LEARNING' 카테고리의 다른 글
Overfitting vs. Underfitting: 개념적 설명 (0) 2018.06.02 데이터 엔지니어 vs 데이터 과학자 (0) 2018.05.02 간단하게 설명한 Random Forest (0) 2018.03.03 파이썬으로 하는 주식 예측 (0) 2018.03.01 파이썬으로 하는 주식분석 (0) 2018.02.23